Chapter 2 : Regular Expressions,Text Normalization,Edit Distance
★ 正则表达式
★ 文本规范化
■ 分句:一般用标点符号分句为主,也可以通过学习进行分句。
■ 分词:主要中文需求。
● 基线方法:MaxMatch
就是从左向右从字典中获取最长的词,如果没有则当前字作为词,然后继续寻找。
缺点:对于未录入的词无法识别。
● 好的常用方法:Sequence model
详见第8章。
■ 词规范化:
● 标点符号保不保留。
● 一些不流利表达保不保留。
● 大小写区不区分。
● 数字保不保留。
● 对于英文,词的形态要不要处理。
词压缩:基于形态学的词型还原,基于重写规则的词干提取。
词分解:BPE(byte-Pair Encoding),制定一系列变形规则,使得常用词不变,低频词分解。
注意:对于语音识别,信息检索等需要进行词规范化。而对于文本分类,信息提取,翻译等任务标点符号、数字、大小写等一般不做处理。
★ 最小编辑距离
用于衡量两个句子的相似度,指两个句子经过多少次变换能够变的一样(动态规划问题)。
Chapter 3 : N-gram Language Models
一种为了计算概率方便的模型。将原来难求的整体概率分解为一段段独立的概率乘积。
Unigram:朴素贝叶斯。Bigram:马尔科夫。一般Trigram比较常用,虽然N越大越好,但计算量会大大增加。
★ Perplexity困惑度
$pp(W)=p(w_1w_2…w_n)^{-1/N}$
用于体现一个模型好坏的指标,对测试样本的句子概率越大,则模型越好,困惑度越小。
★ OOV(out of vocabulary)
■ 指定一个字典,训练时对于不在字典中的词统一标为UNK。
■ 如果没有词典,则可以将训练样本中出现频率低的词标为UNK。
★ Smoothing
因为需要概率连乘,但是训练集并不能包含所有情况,会出现概率为0,所以需要平滑处理。
■ add-1 smoothing/Laplace smoothing
$P_{Laplace}(w_i)=\frac{c_i+1}{N+V}$
■ add-k smoothing
$P_{add-k}(w_i)=\frac{c_i+k}{N+kV}$
上面两种方法都是将高频词的概率分了一部分给低频词。
■ backoff,Interpolation
backoff:如果Trigram不存在则用Bigram再用Unigram。
Interpolation:对于1元、2元、3元分配权重。权重通过最大似然估计用EM算法求得。
$P(w_n|w_{n-2}w_{n-1})=\lambda_1P(w_n|w_{n-2}w_{n-1})+\lambda_2P(w_n|w_{n-1})+\lambda_3P(w_n)$
■ Absolute Discounting
这是一种基于实验结果直觉的处理方式,很神奇,实验发现在一个语料库中出现次数为N的bigram在另一个语料库中往往出现次数为N-0.75。所以这种方法对2到9的计数进行处理。
$P_{AbsoluteDiscounting}(w_i|w_{i-1})=\frac{C(w_{i-1w_i}-d)}{\sum_vC(w_{i-1}v)}+\lambda(w_{i-1})P(w_i)$ d一般取0.75
■ Kneser-Ney Smoothing
这种算法是最常用表现最好的平滑算法,它其实相当于是前面讲过的几种算法的综合。
其基本思想是:一个词的“概率”不止和其出现次数有关,还和其有多少种连接词有关,比如‘京’子在文档中出现次数非常多,但基本上都是以“北京”的形式出现,那么其概率值应该比较小。
具体算法比较复杂,不在这里详细阐述。
Chapter 4 : Naive Bayes and Sentiment Classification
就讲了朴素贝叶斯的一些内容,详见概率图模型 。
Chapter 5 : Logistic Regression
介绍了逻辑回归的一些内容。另外要注意交叉熵、信息熵、KL散度之间的关系。注意生成式、判别式的区别。
Chapter 6 : Vector Semantics
介绍了词向量的训练。另外注意判断向量相似度的最常用指标cosine 。
Chapter 7 : Neural Networks and Neural Language Models
介绍了基础的神经网络。
Chapter 8 : Part-of-Speech Tagging
词性标注。介绍了传统的HMM,MEMM,CRF 。另外注意,直接给予一个词最常用的标注准确率也能达到92.34%。所以一般好的标注算法至少要达到97%。
Chapter 9 : Sequence Processing with Recurrent Networks
RNN,主要介绍了LSTM 。
Chapter 10 :Formal Grammars of English
英语语法……跳过。
Chapter 11 : Syntactic Parsing
句法分析大致可以分为三类:
★ 短语结构句法分析(识别句子中的短语结构以及短语之间的层次句法关系)
★ 句法结构分析(深层分析,比较复杂使用较少)
★ 句法依存分析(浅层分析,简单明了主流的句法分析方法)
这章介绍了句法分析中的句法结构分析 。
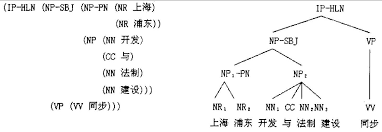
该章介绍了两种实现方法:
● CKY
完全解析,如上图的树状结构。一种动态规划算法,需要优秀的语法集。
● 监督神经网络
部分解析。许多任务并不需要完全解析,所以退化为只解析第一层,类似词性标注。
Chapter 12 : Statistical Parsing
该章介绍了句法结构分析的统计分析方法。比如PCFG(probabilistic context-free grammar)、LFG(Lexical-Functional)、CCG(Combinatory Categorial Grammar)等。
因为很麻烦而且也不太使用了,所以只是简单看了一下PCFG。
PCFG:
有点类似HMM,但规则不限于bigram更加的自由。
三个假设:
● 位置无关性(规则不受位置影响)
● 上下文无关(子节点概率不受其他字符串影响)
● 祖先节点无关性(子节点概率不受祖先节点影响)
三个基本问题:
● 如何求得P(w|G)。 G:语法树,w:字符串。 使用“内向算法”,因为条件独立直接连乘。
● 如何求得最好的G。 viterbi算法,当前划分只与上次划分有关。
● 如何求取规则的概率参数。 EM算法。
整体来说,句法结构分析需要自己定规则(语法集),比较呆板,所以使用较少。
Chapter 13 : Dependency Parsing
该章介绍了依存语法分析 。
依存语法能够处理词形丰富,词序自由的词,而结构语法分析则需要为此添加许多规则。

依存树:
是一个特定的有向图。都是二元关系对。
● 存在一个根节点,没有输入边。
● 除了根节点,每个节点都有1条传入弧。
● 从根节点到每个节点都有唯一路径。
一般为了更加方便引入投影约束。
● 如果p依存于q,那么pq之间的词都不能依存到pq之外的词,即不会出现弧相交的情况。
实现:
● 基于转移的依存分析(Transition-Based Dependency Parsing)
● 基于图的依存分析(Graph-Based Dependency Parsing)
基于转移的依存分析:
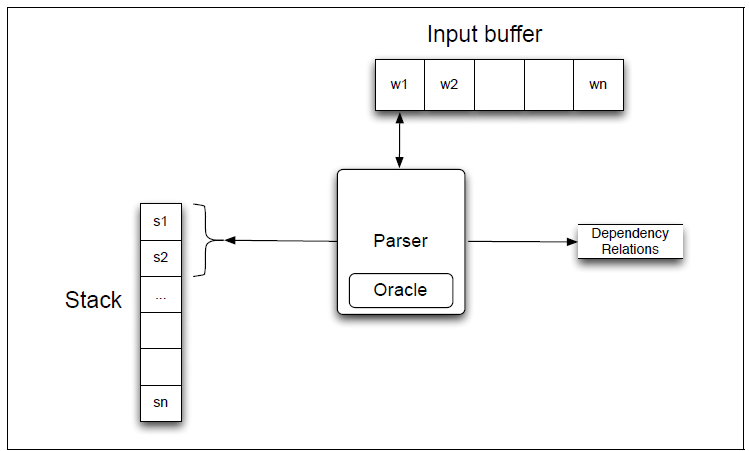
(栈,队列,依存弧)栈:存放待处理的词。队列:从左到右存放单词。依存弧:依存关系(基于语料库)。
3个动作:
● Left-ARC:添加一条s1->s2的依存边,并将s2从栈中删除。即建立右焦点词依存于左焦点词的关系。
● Right-ARC:添加一条s2->s1的依存边,并将s1从栈中删除。即建立左焦点词依存于右焦点词的关系。
● shift:单词出队压入栈。
如果有n种依存关系,则共有2n+1种动作。
注意:得到的序列不一定是唯一正确的。整个分析比较依赖依存关系(语料库)。语料库可以通过treebank转换成我们需要的形式。
使用神经网络实现基于转移的依存分析: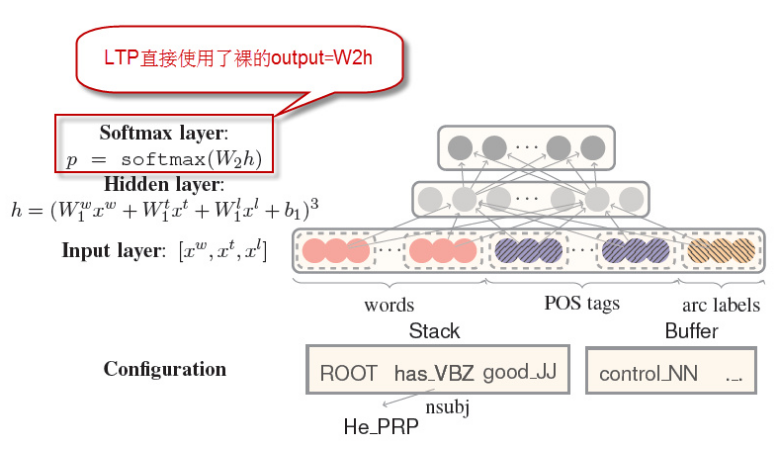
传统的基于转移的依存分析,需要从语料库得到依赖关系。这一步并不是很友好,而使用神经网络可以避免这一步特征提取,大大减少工作量。
<词,词性,依存>做为神经网络的输入。
词:18个单词,用周围词、孩子、孙子来表示当前词。
词性:18个单词所对应的词性。
依存:12个,孩子和孙子的弧标签。
基于图的依存分析:
略过~也有基于神经网络的实现方法。
Chapter 14 : The Representation of Sentence Meaning
略过
Chapter 15、16 未发布
Chapter 17 : Information Extraction
信息提取最常见的就是用于非结构化文本转结构化文本。
NER -> 指代消除、实体连接 -> 关系提取 -> 模板填充
本文主要讲了NER和关系提取 。
NER命名实体识别:
LSTM+CRF
关系提取Relation Extraction:
4种常用方法:
● 手写模式:基于规则、太呆板。
● 监督型机器学习:CNN或bi-Lstm+attention。state-of-art,但是需要标注语料。
● 半监督型机器学习:
■ 基于自助采样:将一些种子匹配生成新的种子,再匹配……(坏)
■ 基于远程监督:用种子对大型数据库(网络)进行匹配生成模板。(好)
● 无监督学习:有点依靠语法。
所以可以使用远程监督的方式获得数据,再用监督的方法去学习。远程监督的难点在于需要一个已有关系的数据库。实际上,半监督、无监督都是想着法子去生成标记数据。
Chapter 18 : Semantic Role Labeling
语义角色标注SRL:一种浅层语义分析技术,以句子为单位,分析句子的<谓词-论元>结构。具体任务就是以句子的谓语为中心,研究句子中各成分与谓词之间的关系,并用语义角色来描述他们之间的关系。
★ 比如:哥伦比亚车手包揽了这次自行车赛的前三名。
REL:包揽 ARG1:哥伦比亚、车手 ARG1:这次、自行车赛、的、前三名
既然是标注问题,也就可以用LSTM+CRF的方法去实现~
角色标注相比于依存分析更加的简洁,当然相应的包含的信息也就更少。
Chapter 23 : Question Answering
对传统方法稍加了解:
● 如何处理Query?重构,推理出回答的类型等,便于之后检索。
● 如何根据问题对文档、段落、句子进行排名。
● 如何从段落句子中提取所需知识。
state-of-art:
★ sequence 2 sequence。使用LSTM+attention的模式进行实现,6的飞起。