什么是概率图模型?
在使用命名实体识别时用到了LSTM+CRF模型。因此需要了解一下CRF,嗯所以顺便简单的了解了一下概率图模型。发现概率图好难,哎只能了解一下皮毛了,实在没精力去十分详细的去学习了~~
概率图模型(Probabilistic Graphical Model,PGM),简称图模型(Graphical Model,GM),是指一种用图结构来描述多元随机变量之间条件独立关系的概率模型,从而给研究高维空间中的概率模型带来了很大的便捷性。
关键:条件独立
概率图模型的关键在于变量之间存在的条件独立性!
比如对一个K维的随机向量 X = [X1,X2……XK] 建模,假设每个变量有m个取值且都不条件独立,那么要得到这个向量的联合概率分布情况则需要存储$m^K-1$ 个参数才行,(因为每个变量的概率都与其他所有的变量有关$p(x)=\prod_{k=1}^{K}p(x_k|x1,……,x_{k-1})$),这个数据量就太大了是不可能存储的。但是如果存在条件独立那么存储量将大大减少,比如极端情况下各个变量两两都条件独立,那么我们只需要存储m*K个参数就可以了,就有了可行性!
三个基本问题:表示、学习、推断
表示问题:对于一个概率模型,如何通过图结构来描述变量之间的依赖关系。
学习问题:图模型的学习包括图结构的学习和参数的学习。
推断问题:在已知部分变量时,计算其他变量的后验概率分布。
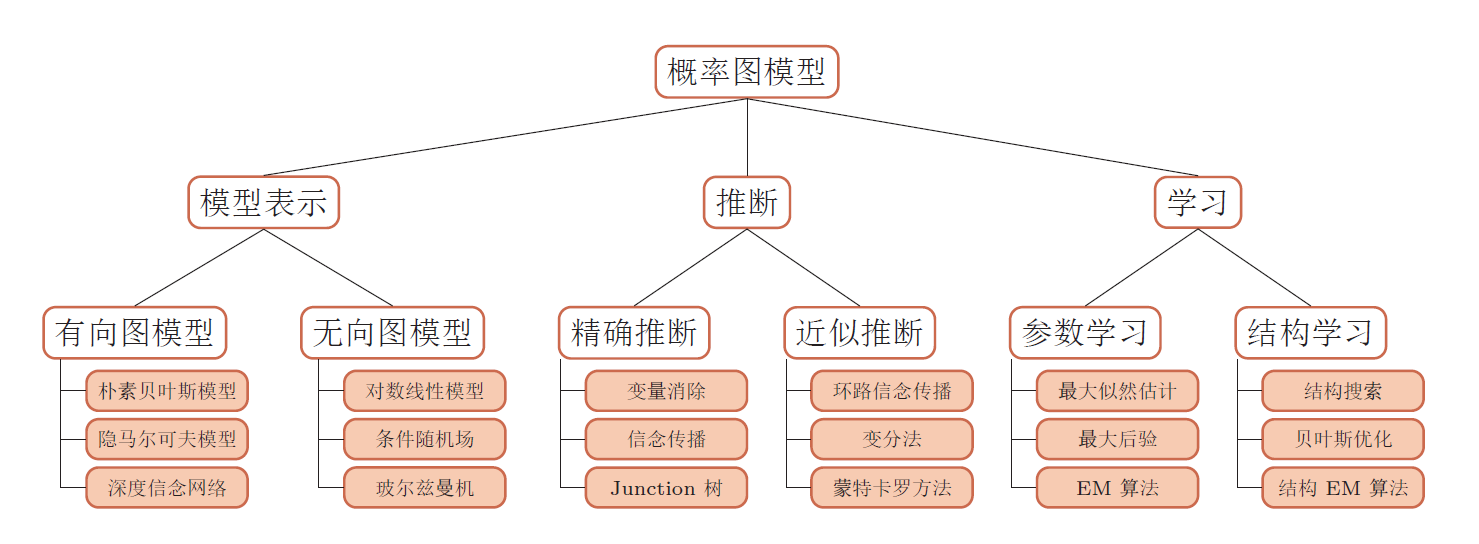
生成式&判别式
生成式:$p(x,y)$ ,朴素贝叶斯、贝叶斯网络、pLSA、LDA、隐马尔可夫模型。
判别式:$p(y|x)$,最大熵模型、CRF。
PGM的一些见解
机器学习的一个核心任务是从观测到的数据中挖掘隐含的知识,而概率图模型是实现这一任务的一种很elegant,principled的手段。
PGM巧妙地结合了图论和概率论。从图论的角度,PGM是一个图,包含结点与边。结点可以分为两类:隐含结点和观测结点。边可以是有向的或者是无向的。从概率论的角度,PGM是一个概率分布,图中的结点对应于随机变量,边对应于随机变量的dependency或者correlation关系。
给定一个实际问题,我们通常会观测到一些数据,并且希望能够挖掘出隐含在数据中的知识。怎么用PGM实现呢?我们构建一个图,用观测结点表示观测到的数据,用隐含结点表示潜在的知识,用边来描述知识与数据的相互关系,最后获得一个概率分布。给定概率分布之后,通过进行两个任务:inference (给定观测结点,推断隐含结点的后验分布)和learning(学习这个概率分布的参数),来获取知识。
PGM的强大之处在于,不管数据和知识多复杂,我们的处理手段是一样的:建一个图,定义一个概率分布,进行inference和learning。这对于描述复杂的实际问题,构建大型的人工智能系统来说,是非常重要的。
以上采自谢澎涛
因为图模型中的每个变量一般有着明确的解释,变量之间依赖关系一般是人工来定义。 所以概率图模型相对于其他模型往往有着更好解释的优点,但是如何构建一个好的图,如何进行inference和learning很麻烦。看了很多别人用概率图模型解决问题的感想,给了我一种很麻烦而且准确度也不怎么样的感觉!相比于神经网络什么的,概率图不是一种黑箱子问题,他无法通过简单的调调参数就能解决问题,他更加的贴近人的正常思维,而这正是他的优势和劣势所在!
模型表示
概率图模型是一类用图来表达变量相关关系的概率模型。它以图为表示工具,最常见的是用一个结点表示一个或一组随机变量,结点之间的边表示变量之间的概率相关关系,即”变量关系图“。
概率图模型可大致分为两类:
一. 有向无环图,称为有向图模型或贝叶斯网(Bayesian network)
二. 无向图,称为无向图模型或马尔可夫网(Markov network)
有向图模型&贝叶斯网
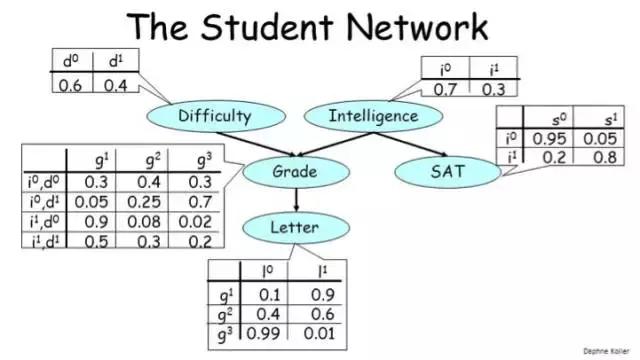
贝叶斯网(Bayesian network)亦称“信念网(belief network)”,它借助有向无环图(Directed Acyclic Graph,DAG)来刻画属性之间的依赖关系,并使用条件概率表(Conditional Probability Table,CPT)来描述属性的联合概率分布。
在前面提到了,概率图模型的关键在于条件独立性! 而贝叶斯网结构有效地表达了属性间的条件独立性。给定父结点集πi,贝叶斯网假设每个属性与它的非后裔属性独立。$P(x1,x2…,xd) = \prod_{i=1}^{d}P(xi|\pi_i)$
则上图的联合概率分布为:$P(d,g,i,s,l) = P(d)P(i)P(g|d,i)P(s|i)P(l|g)$
朴素贝叶斯分类器
naive Bayes classifier
一般的贝叶斯网已经很好的简化了各个属性之间的关系,充分体现了条件独立性。但是朴素贝叶斯分类器更加过分,它采用了”属性条件独立性假设(attribute conditional independence assumption):假设所有属性相互独立!“嗯,所实话我觉得这货都不能算在贝叶斯网里了,因为它压根没有网络结构。。。
如何使用?
对于分类问题,我们经常使用最大后验概率来获得分类结果。
$P(c|x) = \frac{P(c)P(x|c)}{P(x)} = \frac{P(c)}{P(x)}\prod_{i=1}^{d}P(x_i|c)$ (因为互相独立,所以直接概率相乘即可。)
$h_{nb}(x) = arg_{c\in{Y}}max P(c)\prod_{i=1}^{d}P(x_i|c)$
其中,c为分类结果,x为输入值。P(x)为常量,可以忽视。
P(c)先验概率:可以通过样本统计获得。
$P(c) = \frac{|D_c|}{D}$ ,Dc表示训练集D中第c类样本组合成的集合。
为了避免其他属性携带的信息被训练集中未出现的属性“抹去”,常用拉普拉斯修正(Laplacian correction)进行平滑(smoothing)处理。
$P(c) = \frac{|D_c|+1}{|D|+N}$ (N为类别数)
P(xi|c)条件概率:也可以通过样本统计获得。
$P(x_i|c) = \frac{|D_{c,x_i}|}{|D_c|}$ (统计在同一类中属性出现的概率)
同样用拉普拉斯修正后。
$P(x_i|c) = \frac{|D_{c,x_i}|+1}{|D_c|+N_i}$ (Ni表示第i个属性可能的取值数)
另外,对于连续属性可以考虑用概率密度函数。比如可以假设$P(x_i|c) \sim N(\mu_{c,i},\sigma_{c,i}^2)$ ,μ和σ分别c类第i个属性的均值和方差,则有。
$P(x_i|c) = \frac{1}{\sqrt{2\pi}\sigma_{c,i}}exp(-\frac{(x_i-\mu_{c,i})^2}{2\sigma_{c,i}^2})$
所以朴素贝叶斯实现起来很简单,就是对样本进行统计 。
例子
比如用于文本的分类,分为脏话和非脏话。
样本:
‘你’,‘是’,‘猪’ => 1,脏话
‘你’,‘是’,’人’=> 0,非脏话
输入:
’我‘,’是‘,’猪‘
运行:
$P(1)=0.5 P(0)=0.5$
$P(我|1) =\frac{0+1}{3+4}=1/7$ $P(是|1) = \frac{1+1}{3+4} = 2/7$ $P(猪|1) = \frac{1+1}{3+4} = 2/7$
$P(我|0) =\frac{0+1}{3+4}=1/7$ $P(是|0) = \frac{1+1}{3+4} = 2/7$ $P(猪|0) = \frac{0+1}{3+4} = 1/7$
因为$P(1|’我是猪’) >P(0|’我是猪’) $ 所以‘我是猪’是脏话!
后记
摘自西瓜书
朴素贝叶斯分类器引入属性条件独立性假设,这个假设在现实应用中往往很难成立,但有趣的是,朴素贝叶斯分类器在很多情形下都能获得相当好的性能!一种解释是对分类任务来说,只需各类别的条件概率顺序正确、无须精准概率值即可导致正确分类结果。另一种解释是,若属性间依赖对所有类别影响相同或依赖关系的影响能互相抵消,则属性条件独立性假设在降低计算开销的同时不会对性能产生负面影响。
半朴素贝叶斯分类器
semi-naive Bayes classifiers
由于时间问题不对这一部分内容深入学习,大约了解一下。
在朴素贝叶斯分类器中,进行了属性的独立性假设,虽然这大大简化了计算复杂度,但和现实任务差距有点大,所以就出现了半朴素贝叶斯分类器。他的策略是独依赖估计(One-Dependent Estimator ODE),简单的说就是每个属性在类别之外最多仅依赖于一个其他属性。这样的话计算不会变的太复杂,还能提高适用性
隐马尔可夫模型
这部分内容主要参考《西瓜书》和《统计学习方法》和 刘建平Pinard
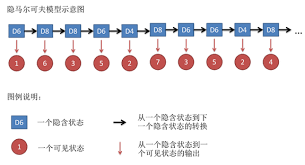
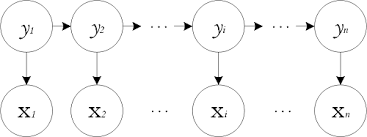
隐马尔可夫模型(Hidden Markov Model,HMM)是结构最简单的动态贝叶斯网,可以是监督的也可以是非监督的!
基础概念
状态变量: $ \lbrace y_1,y_2,…,y_n \rbrace ,长度n$
状态空间: $\lbrace s_1,s_2,…,s_N \rbrace,N个取值$
观测变量: $\lbrace x_1,x_2,…,x_n \rbrace$
观测空间: $\lbrace o_1,o_2,…,o_M \rbrace,M个取值$
整个网络基于两个假设:
假设1:齐次马尔科夫链假设。 即任意时刻的隐藏状态只依赖于它前一个隐藏状态。
假设2:观测独立性假设。即任意时刻的观察状态只仅仅依赖于当前时刻的隐藏状态。
整个网络基于三组参数:
● 状态转移概率 : 模型在各个状态间转换的概率,通常记为矩阵 $A=[a_{i,j}]_{N*N}$
$$a_{i,j} = P(y_{t+1} = s_j | y_t = s_i),1\le i,j \le N$$
即表示在任意时刻t,若状态为si,则在下一时刻状态为sj的概率。
● 输出观测概率 : 模型根据当前状态获得各个观测值的概率,通常记为矩阵 $B = [b_{i,j}]_{N*M}$
$b_{i,j} = P(x_t = o_j|y_t = s_i), 1\le i\le N,1\le j \le M$
即表示在任意时刻t,若状态为si,则观测值oj被获取的概率。
● 初始状态概率 : 模型在初始时刻各状态出现的概率,通常记为 $\pi = (\pi_1,\pi_2,…,\pi_N)$
$\pi_i = P(y_1 = s_i),1\le i \le N$
即表示模型的初始状态为si的概率。
☆ 状态空间,观测空间,三组参数$\lambda = [A,B,\pi]$ ,就能确定一个隐马尔可夫模型。
三个基本问题
● 评估观察序列概率
即给定模型$λ=(A,B,\pi)$和观测序列$x={x_1,x_2,…x_n}$,计算在模型λ下观测序列x出现的概率$P(x|λ)$。
应用:比如已知观测序列$x_1,x_2,…,x_{n-1}$ ,来推测最有可能的$x_n$。
解决:前向后向算法
● 模型参数学习
即给定观测序列$x={ x_1,x_2,…,x_n}$,估计模型$λ=(A,B,\pi)$的参数,使观测序列的条件概率$P(x|λ)$最大。在这里主要针对的是非监督的HMM,因为对于监督型的HMM即状态序列已知,则只需要直接求概率即可。
解决:鲍姆-韦尔奇算法
● 预测、解码问题
即给定模型$λ=(A,B,\pi)$和观测序列$x={x_1,x_2,…x_n}$,求给定观测序列条件下,最可能出现的对应的状态序列。
应用:在语言识别等任务中,观测值为语音信号,隐藏状态为文字,由语音推最可能的文字。
解决:维特比算法
前向后向算法
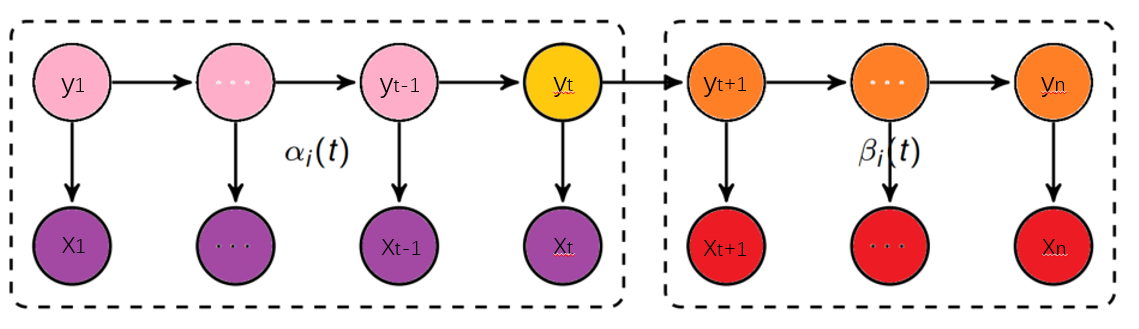
用于解决评估观察序列概率问题。
简单来看,我们都已经得到模型$λ=(A,B,\pi)$和观测序列$x={x_1,x_2,…x_n}$,求一个概率$P(x|λ)$还不简单?
暴力求解:$P(x|λ)=\sum_{y}P(x,y|λ)=\sum_{y_1,y_2,…y_n}π_{y_1}b_{y_1}(x_1)a_{y_1,y_2}b_{y_2}(x_2)…a_{y_{n-1}y_n}b_{y_n}(x_n)$
不过不用想也知道这样肯定不行,算法复杂度:$O(nN^n)$ ,爆炸~
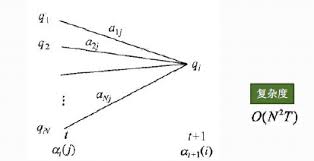
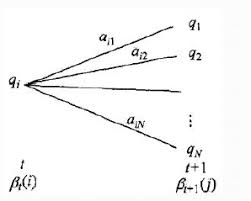
前向后向算法是前向算法和后向算法的统称,属于动态规划 。也就是我们要通过找到局部状态递推的公式,这样一步步的从子问题的最优解拓展到整个问题的最优解。复杂度降到了:$O(N^2*n)$
前向概率: $\alpha_i(t) = P(x_1,x_2,…x_t,q_t=i|\lambda )$
即第t个时刻的状态为i时,前面的观测序列为{x1,x2, …, xt}的概率
流程:
- 计算时刻1的各个隐藏状态前向概率:$α_1(i)=π_ib_i(y_1),i=1,2,…N$
- 递推时刻2,3,…n时刻的前向概率:$\alpha_{t+1}(i)=[\sum_{j=1}^{N}\alpha_t(j)a_{ji}]b_i(x_{t+1}),i=1,2,…N$
- $[\sum_{j=1}^{N}\alpha_t(j)a_{ji}]$
- 最终结果: $P(x|λ)=\sum_{i=1}^Nα_T(i)$
后向概率: $ \beta_i(t) = P(x_{t+1},x_{t+2},…x_T|q_t = i,\lambda)$
当第t个时刻的状态为i时,后面的观测序列为{xt+1,xt+2, …, xn}的概率
流程:
- 初始化时刻n的各个隐藏状态后向概率:$β_T(i)=1,i=1,2,…n$
- 递推时刻T−1,T−2,…1时刻的后向概率:$\beta_t(i)=\sum_{j=1}^Na_{ij}b_j(x_{t+1})\beta_{t+1}(j),i=1,2,…N$
- 最终结果:$P(x|λ)=\sum_{i=1}^Nπ_ib_i(x_1)β_1(i)$
理解: 实际上前向后向算法作为动态规划算法,思路还是很清楚的。每个时间点的前向概率,就是将之前时间点的情况进行了汇总,这样一来后一个时间点就可以直接处理汇总的信息,而不用像暴力方法那样从头算起~
应用:
给定模型λ和观测序列x,在时刻t处于状态i的概率记为:
$\gamma_t(i)=\frac{\alpha_t(i)\beta_t(i)}{\sum_{j=1}^N\alpha_t(j)\beta_t(j)}$
给定模型λ和观测序列x,在时刻t处于状态i,且时刻t+1处于状态j的概率记为:
$\xi_t(i,j)=\frac{\alpha_t(i)a_{ij}b_j(x_{t+1})\beta_{t+1}(j)}{\sum_{r=1}^N\sum_{s=1}^N\alpha_t(r)\alpha_{rs}b_s(x_{t+1})\beta_{t+1}(s)}$
将$γt(i)和ξt(i,j)$在各个时刻t求和,可以得到:
●在观测序列x下状态i出现的期望值$\sum_{t=1}^nγ_t(i)$
●在观测序列x下由状态i转移的期望值$\sum_{t=1}^{n−1}γ_t(i)$
●在观测序列x下由状态i转移到状态j的期望值$\sum_{t=1}^{n−1}ξ_t(i,j)$
鲍姆-韦尔奇算法
鲍姆-韦尔奇算法的目的是进行参数学习。
实际上,HMM有两种情况:一种是监督的即隐藏状态已标注,比如由英文=>中文,可以获得标注语料。另一种是非监督的即隐藏状态未标注,比如对于语音是很难标注的因为是连续的。
对于监督型的HMM: 我们可以用最大似然来求解参数。
假设样本从隐藏状态i转移到j的频率计数是Aij,那么状态转移矩阵求得为:
状态转移矩阵: $A=[a_{ij}],其中a_{ij}=\frac{A_{ij}}{\sum_{s=1}^NA_{is}}$
假设样本隐藏状态为j且观测状态为k的频率计数是Bjk,那么观测状态概率矩阵为:
观测状态概率矩阵 : $B=[b_j(k)],其中b_j(k)=\frac{B_{jk}}{\sum_{s=1}^MB_{js}}$
假设所有样本中初始隐藏状态为i的频率计数为C(i),那么初始概率分布为:
初始概率分布: $\Pi=\pi(i)=\frac{C(i)}{\sum_{s=1}^NC(s)}$
对于非监督型的HMM:我们需要用鲍姆-韦尔奇算法
实际上鲍姆-韦尔奇算法就是EM算法,两者的原理是一样的,只是换了一个马甲而已。。
所以我们需要不断的循环互求隐藏状态和模型参数 。
流程:
随机初始化所有的$\pi_i,a_{ij},b_j(k)$
对于每个样本d=1,2,…D,用前向后向算法计算$γ_t^{(d)}(i),ξ_t^{(d)}(i,j),t=1,2…n$,也就是求了隐藏值。
更新模型参数:
$\pi_i=\frac{\sum_{d=1}^Dγ_t^{(d)}(i)}{D}$
$a_{ij}=\frac{\sum_{d=1}^D\sum_{t=1}^{T−1}\xi_t^{(d)}(i,j)}{\sum_{d=1}^D\sum_{t=1}^{T−1}\gamma_t^{(d)}(i)}$
$b_j(k)=\frac{\sum_{d=1}^D\sum_{t=1,o_t^{(d)}=v_k}^T\gamma_t^{(d)}(i)}{\sum_{d=1}^D\sum_{t=1}^T\gamma_t^{(d)}(i)}$
如果$\pi_i,a_{ij},b_j(k)$的值已经收敛,则算法结束,否则回到第2步继续迭代。
维特比算法
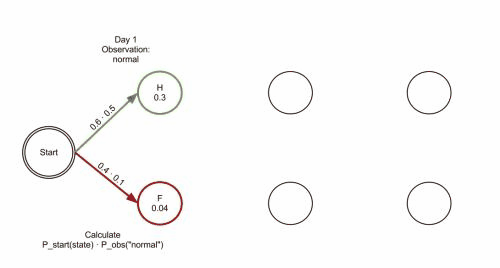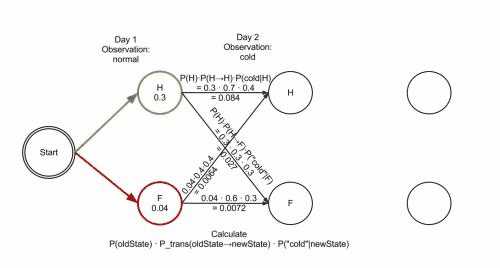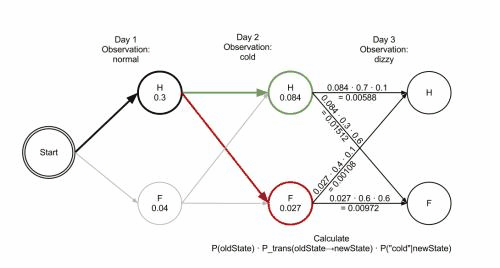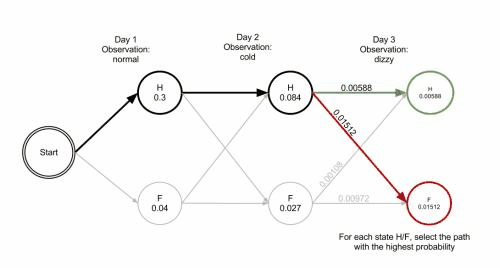
维特比算法Viterbi algorithm是一个通用的求序列最短路径的动态规划算法,经常用于解码问题,比如在CRF中。既然是动态规划算法,那么就需要找到合适的局部状态,以及局部状态的递推公式。
流程:
输入:HMM模型λ=(A,B,Π),观测序列O=(o1,o2,…oT)
输出:最有可能的隐藏状态序列$I^∗={i^∗1,i^∗2,…i^∗T}$
初始化局部状态:
$δ_1(i) = \pi_ib_i(o_1),i=1,2…N$
$\psi_1(i)=0,i=1,2…N$
进行动态规划递推时刻t=2,3,…T时刻的局部状态:
$\delta_t(i)=max_{1≤j≤N}[\delta_{t−1}(j)a_{ji}]b_i(O_t),i=1,2…N$
$\psi_t(i)=argmax_{1≤j≤N}[\delta_{t−1}(j)a_{ji}],i=1,2…N$
计算时刻T最大的δT(i),即为最可能隐藏状态序列出现的概率。时刻T最大的Ψt(i),即为时刻T最可能的隐藏状态。
$P∗=max_{1≤j≤N}δ_T(i)$
$i_T^*=argmax_{1≤j≤N}[\delta_T(i)]$
利用局部状态Ψ(i)开始回溯。对于t=T−1,T−2,…,1t=T−1,T−2,…,1:
$i_t^∗=\psi_{t+1}(i_{t+1}^∗)$
终得到最有可能的隐藏状态序列 $I^∗={i^∗_1,i^∗_2,…i^∗_T}$
理解: 同作为动态规划,维特比算法和前向后向算法,思路一致。区别在于前向后向算法每个时间每个状态保存的是概率的总和,而维特比算法则保存的是最大的概率值和路径。 因为前向后向算法需要的是一个状态出现的期望,而维特比则是需要一个状态出现的最大概率!
最大熵模型
MEMM(Maximum Entropy Markov Model)。
HMM中存在两个缺点:
- 每个观测值只依赖于对应的隐藏值,这个假设过于严格,序列标注问题不仅和单个词相关,而且和观察序列的长度,单词的上下文,等等相关。
- 学得的是联合分布$P(x,y)$,而我们需要的是条件$P(y|x)$。
所以MEMM就此进行了改进:每个隐藏值依赖于前一个预测值和所有观测值。
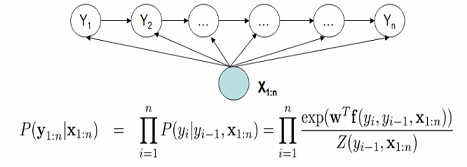
MEMM的假设要求较宽,因此获得了更强的表达能力,训练结果优于HMM,(虽然麻烦了很多)。
但MEMM作为贝叶斯网络存在一个巨大缺陷:标注偏置。
标注偏置
作为贝叶斯网络,MEMM需要获得各个隐藏节点的概率值,而这个概率值是通过局部归一化得到的。
局部归一化存在一个问题:如果某个节点其可达节点比较多(比如2节点),那么其势必会导致概率的分散,相比于可达节点少的节点(比如1节点)就比较吃亏。而节点之间是否可达,则取决于模型人工设置的特征。
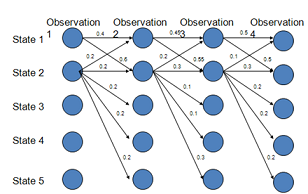
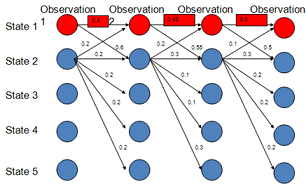
总结
MEMM就像一个HMM和CRF的过度模型,放宽了假设却仍被局部概率所束缚,所以其使用起来很尴尬。简便不如HMM,因为其要人工设置特征,而同样人工设置特征其效果又没有CRF好(CRF使用全局归一化,不存在标注偏置)。。。
无向图模型&马尔可夫网
马尔可夫网络无向且可以有环 。
马尔可夫网络使用势函数(potential function)或因子(factor)来表示节点之间的关系,和贝叶斯网的概率不同,势函数不需要总和为1,势函数只是告诉我们值更高的配置有更高的可能性。
在马尔可夫网中,节点之间并没有因果关系,它们之间的作用是对称的。
既然是概率图模型,那么就需要讨论一下条件独立性:
● 全局马尔科夫性(global Markov property) : 给定两个变量子集的分离集,则这两个变量子集条件独立。换句话说就是,只与相邻的集有关!
● 局部马尔可夫性(local Markov property): 给定某变量的邻接变量,则该变量条件独立于其他变量。这些邻接变量的集合称为马尔可夫毯(Markov blanket) 。十分形象,相邻变量就像毯子一样将变量包裹起来。
● 成对马尔可夫性(pairwise Markov property): 给定所有其他变量,两个非邻接变量条件独立。
马尔可夫随机场
马尔可夫随机场(Markov Random Field,MRF)是典型的马尔可夫网。
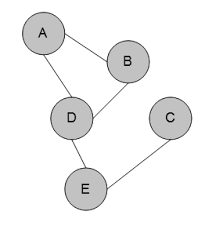
马尔可夫随机场由一个个的团(clique)组成。团指的是一个结点的子集,且其中任意两节点都有边连接,如图中的{A,B},{A,D},{A,B,D},{D,E},{E,C}。
而若是在一个团中加入另外任何一个结点都不再是团,那么这个团是极大团(maximal clique) ,如图中的{A,B,D},{D,E},{E,C}
为什么要设定“团”这个概念?
因为Hammersley-clifford Theorem 证明了:如果图上结点的概率只与相邻结点有关,则无向图的一个概率分布P(x),符合吉布斯分布,能够因子分解为定义在团上的正函数乘积!
而且由于普通团一定能够包含在极大团中,这也就意味着普通团的关系也能够体现在极大团中,这样一来就能更进一步:联合概率P(x),能够用极大团来定义!
有了团的存在可以大大减少求联合概率的负担!!
怎么表示一个团?
既然联合概率可以用极大团来定义,那么我们应该怎么定义极大团呢?
在马尔可夫网中,我们用势函数(potential function)或因子(factor)来表示一个极大团。
因为势函数是非负的,所以为了满足非负性,常用指数函数来定义势函数。
$\psi_Q(x-Q)=e^{-H_Q(x_Q)}$
$H_Q(x_Q) = \sum_{u,v\in Q,u\ne v}\alpha_{u,v}x_ux_v+\sum_{v\in Q}\beta_vx_v, 其中u,v是极大团Q中的结点$
$H_Q$被称为能量函数(energy function)。其第一项考虑了每一对结点的关系,而第二项则仅考虑单结点。
$\psi_Q$ 为势函数,服从玻尔兹曼分布(Boitzman distribution)。
怎么用势函数定义联合概率?
我们已经有了势函数,那么怎么由此获得联合概率?
$P(x) = \frac{1}{Z^\ast}\prod_{Q\in C^\ast}\psi_Q(x_Q)$
$Z^\ast = \sum_x \prod_{Q\in C^\ast}\psi_Q(x_Q)$
C*为极大团的集合。Z*为规范化因子,以确保P(x)以概率的形式表示。当然Z很难求,还好一般并不需要求出Z值。
条件随机场
这部分内容主要参考《西瓜书》和《统计学习方法》和 刘建平Pinard
条件随机场(Condiitonal Random Field,CRF) 是马尔科夫随机场的特例,可以看成给定观测值的马尔可夫随机场。条件随机场假设马尔科夫随机场中只有X和Y两种变量,X一般是给定的,而Y一般是在给定X的条件下我们的输出。
定义:设X与Y是随机变量,P(Y|X)是给定X时Y的条件概率分布,若随机变量Y构成的是一个马尔科夫随机场,则称条件概率分布P(Y|X)是条件随机场。(所以条件随机场是判别式模型)
因为一般的条件随机场实在有点复杂,所以一般使用链式条件随机场(chain-structured CRF)!
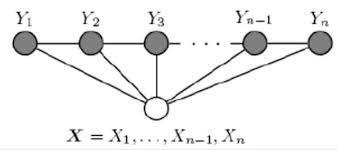
链式条件随机场要求X和Y的长度相同。(嗯,这样一来是不是觉得和HMM很像?)
如何表示P(x|y)?
和HMM的转移矩阵相似,CRF也有特征矩阵。
节点特征函数 : 表示当前结点的特征。
$s_l(y_i,x,i),l=1,2,…L$
其中L是定义在该节点的节点特征函数的总个数,i是当前节点在序列的位置。取值0或1
局部特征函数: 表示相邻结点的特征。
$t_k(y_{i−1},y_i,x,i),k=1,2,…K$
其中K是定义在该节点的局部特征函数的总个数,i是当前节点在序列的位置。取值0或1
节点特征函数权重 $μ_l$ : 表示对节点特征函数的信任度。
局部特征函数权重 $λ_k$: 表示对局部特征函数的信任度。
▲注:之所以单独设置权重,是因为特征函数是提前定的,而权重是需要通过学习得到的。
由这四个参数我们可以求出条件概率:
$P(y|x)=\frac{1}{Z(x)}exp(\sum_{i,k}λ_kt_k(y_{i−1},y_i,x,i)+\sum_{i,l}μ_ls_l(y_i,x,i)),其中Z(x)为规范化因子$
嗯。就是暴力求解~
特征函数例子。为什么有两个参数?
假设输入的都是三个词的句子,即X=(X1,X2,X3),输出的词性标记为Y=(Y1,Y2,Y3),其中Y∈{1(名词),2(动词)}
取值为1的特征函数如下:
$t_1=t_1(y_{i−1}=1,y_i=2,x,i),i=2,3$
$t_2=t_2(y_{i-1}=2,y_i=1,x,i),i=3$
$t_3=t_3(y_{i-1}=2,y_i=1,x,i),i=2$
$t_4 = t_4(y_{i-1} =2,y_i=2,x,i),i=2,x_i=’人’$
可以看出每个特征函数就是制定一个规则,每一条规则内的i,x都是不定的。
但是$y_{i-1}和y_i$的可能种类是确定的,最多m*m种(m为y所有可能的状态的取值个数),这意味着可以将这些特征进行合并!
如何简化(用矩阵)表示条件概率?
已经知道特征方程可以压缩到m*m种,所以可以从这个方向对条件概率进行简化。
● 对特征方程进行整合
$$ f_k(y_{i−1},y_i,x,i)=\begin{cases}t_k(y_{i−1},y_i,x,i) , k=1,2,…K_1\ s_l(y_i,x,i),k=K_1+l,l=1,2…,K_2 \end{cases}$$
K1为局部特征个数,K2为节点特征个数
● 对权重进行整合
$$ \omega_k=\begin{cases}\lambda_k , k=1,2,…K_1\ \mu_l,k=K_1+l,l=1,2…,K_2 \end{cases}$$
K1为局部特征个数,K2为节点特征个数
● 构建m*m矩阵
$M_i(x)=[M_i(y_{i−1},y_i|x)]=[exp(W_i(y_{i−1},y_i|x))]=[exp(\sum_{k=1}^Kw_kf_k(y_{i−1},y_i,x,i))]$
★注意:对于每个节点i都有一个m*m的矩阵!(由实际的x序列,i决定)
● 用矩阵表示概率函数
$P_w(y|x)=\frac{1}{Z_w(x)}\prod_{i=1}^nM_i(y_{i−1},y_i|x)$
注意:相乘的并不是矩阵,只是每个矩阵中的一个值(由目标y决定)。
前向后向算法
和HMM相似,前向后向算法用于解决评估观察序列问题。
定义:$α_i(y_i|x)$表示序列位置i的标记是yi时,在位置i之前的部分标记序列的非规范化概率。
定义:$\beta_i(y_i|x)$表示序列位置i的标记是yi时,在位置i之后的从i+1到n的部分标记序列的非规范化概率。
(因为规范化概率求起来很麻烦,而且没必要,所以只求非规范化概率。)
推导:
我已经有:
$M_i(y_{i−1},y_i|x)=exp(\sum_{k=1}^Kw_kf_k(y_{i−1},y_i,x,i))$
来表示给定$y_{i−1}$时,从$y_{i−1}$转移到$y_i$的非规范化概率。
则α的递推公式:
$\alpha_{i+1}(y_{i+1}|x)=\alpha_i(y_i|x)M_{i+1}(y_{i+1},y_i|x),i=1,2,…,n+1$
则$\alpha_{i}$ 是一个1m维的向量,而M是个m\m的矩阵。
则$\alpha$可以这样表示 :
$α^T_{i+1}(x)=α^T_i(x)M_{i+1}(x)$
同理β可以这样表示:
$\beta_i(x)=M_{i+1}(x)\beta_{i+1}(x)$
ps:在起点和终点可以假设α,β为1。
规范化因子:
$Z(x)=\sum_{c=1}^m\alpha_n(y_c|x)=\sum_{c=1}^m\beta_1(y_c|x)$
结论:
● 序列位置i的标记是yi时的条件概率P(yi|x):
$P(y_i|x)=\frac{\alpha^T_i(y_i|x)β_i(y_i|x)}{Z(x)}=\frac{\alpha^T_i(y_i|x)β_i(y_i|x)}{α^T_n(x)\bullet\overrightarrow{1}}$
● 序列位置i的标记是yi,位置i−1的标记是yi−1时的条件概率P(yi−1,yi|x):
$P(y_{i−1},y_i|x)=\frac{α^T_{i−1}(y_{i−1}|x)M_i(y_{i−1},y_i|x)β_i(y_i|x)}{Z(x)}=\frac{α^T_{i−1}(y_{i−1}|x)M_i(y_{i−1},y_i|x)β_i(y_i|x)}{α^T_n(x)\bullet\overrightarrow{1}}$
● 条件分布P(y|x)的期望:
$\begin{align}E_{P(y|x)}[f_k]&=E_{P(y|x)}[f_k(y,x)]\&=\sum_{i=1}^{n}\sum_{y_{i−1}yi}P(y_{i−1},y_i|x)f_k(y_{i−1},y_i,x,i)\&=\sum_{i=1}^n\sum_{y_{i−1}y_i}f_k(y_{i−1},y_i,x,i)\frac{\alpha^T_{i−1}(y_{i−1}|x)M_i(y_{i−1},y_i|x)\beta_i(y_i|x)}{\alpha^T_n(x)\bullet\overrightarrow{1}} \end{align}$
● 联合分布P(x,y)的期望:
$\begin{align} E_{P(x,y)}[f_k]&=\sum_{x,y}P(x,y)\sum_{i=1}^nf_k(y_{i−1},y_i,x,i) \&=\sum_x\overline{P}(x)\sum_yP(y|x)\sum_{i=1}^nf_k(y_{i−1},y_i,x,i)\&=\sum_x\overline{P}(x)\sum_{i=1}^n\sum_{y_{i−1}y_i}f_k(y_{i−1},y_i,x,i)\frac{\alpha^T_{i−1}(y_{i−1}|x)M_i(y_{i−1},y_i|x)\beta_i(y_i|x)}{\alpha^T_n(x)\bullet\overrightarrow{1}} \end{align}$
参数学习
CRF是监督学习,需要学习的是模型参数$\omega_k$
使用最大似然,则需要求$P_w(y|x)$
$P_\omega(y|x)=P(y|x)=\frac{1}{Z_w(x)}exp\sum_{k=1}^K\omega_kf_k(x,y)=\frac{exp\sum_{k=1}^K\omega_kf_k(x,y)}{\sum_y exp\sum_{k=1}^K\omega_kf_k(x,y)}$
分母需要用巧妙的方法求得,这里暂时略过。
对参数$\omega_k$,可以使用梯度下降法,牛顿法,拟牛顿法,迭代尺度法(IIS),来求解!
维特比算法
与HMM一样,都是求序列最短路径 ,都是解码问题,所以可以用维特比算法Viterbi algorithm,来进行解码!
流程:
输入:模型的K个特征函数,和对应的K个权重。观测序列x=(x1,x2,…xn),可能的标记个数m。
输出:最优标记序列$y^∗=(y^∗_1,y^∗_2,…y^∗_n)$
初始化:
$\delta_1(l)=\sum_{k=1}^Kw_kf_k(y_0=start,y_1=l,x,i),l=1,2,…m$
$\psi_1(l)=start,l=1,2,…m$
对于i=1,2…n−1,进行递推:
$\delta_{i+1}(l)=max_{1≤j≤m}{\delta_i(j)+\sum_{k=1}^Kw_kf_k(y_{i}=j,y_{i+1}=l,x,i)},l=1,2,…m$
$\psi_{i+1}(l)=argmax_{1≤j≤m}{\delta_i(j)+\sum_{k=1}^Kw_kf_k(y_i=j,y_{i+1}=l,x,i)},l=1,2,…m$
终止:
$y^\ast_n=argmax_{1≤j≤m}\delta_n(j)$
回溯:
$y^\ast_i=\psi_{i+1}(y^\ast_{i+1}),i=n−1,n−2,…1$
最优标记序列$y^∗=(y^∗_1,y^∗_2,…y^∗_n)$
线性CRF与HMM 的区别
我们可以明显的感受到,线性CRF与HMM十分像,从模型的结构到后期的推导都十分的相近。
最大的不同点是linear-CRF模型是判别模型,而HMM是生成模型,可以这么理解:linear-crf得到一个输入序列x时,特征矩阵就会相应改变,从而在推导求解时就与x无关了,也就是求P(y|x)。 而HMM的参数矩阵是确定的,在求解推导时与x有关,也就是求P(y,x)。
另外,linear-CRF的特征是对整个观测序列x,而HMM的观测序列做了马尔科夫假设。 所以linear-CRF学习了观测序列和输出序列的时间特征,而HMM只学习了输出序列的时间特征!
因此理论上CRF的使用范围要比HMM广泛的多,HMM可以“理解为”一个特殊的CRF。
TensorFlow.crf 源码简析
1 | # 对TensorFlow crf.py的主要函数进行简析 |
模型学习
模型学习一般可分为参数学习(估计)和结构学习。
结构学习一般比较困难,一般由领域专家来构建,这里只是简单了解一下。
参数学习在无隐变量的情况下,直接用极大似然或最大后验。存在隐变量的情况下,则需要EM算法等。
另外,如果将参数也看作待推测的变量,那么参数估计也可以看作推断!
参数学习
极大似然与最大后验
极大似然估计 Maximum Likelihood Estimate
最大后验概率估计 Maximum A Posteriori estimation
在看概率图模型时,经常会看到最大似然估计和最大后验估计。因为概率论的东西基本全还给老师了,所以看的一愣一愣的。没办法只好查资料补起来,说实话这两个东西初看看挺简单的,以为已经理解了,但是当我尝试去分析一个问题时又会有点茫然。。真是头大,到写这些东西,我仍觉得并没有真正理解这两个概念。。。。。
起源
极大似然估计(MLE)– 频率学派
最大后验概率估计(MAP)– 贝叶斯派
事实上,我对这两个学派并没有什么兴趣。他们只是根据自己的理解分别提出了各自的观点而已。
频率派认为参数是个客观存在的固定值,而贝叶斯派则认为参数是服从一个分布的随机值。
相比于频率派贝叶斯派增加了参数的先验分布,然后根据数据计算参数的后验分布 。这个先验分布一般根据历史数据统计得到,也可以人为经验给定,这使的结果并不完全依赖于样本数据,于是往往用后验估计更加可靠。但问题在于怎么获得这个先验假设?好的先验假设确实有用,但拍拍脑袋想出来的先验假设就只能呵呵了~
另外,这两个学派至今未能达成共识! 想起自己刚看这两个估计时傻傻的想把他们合在一起理解真是头大。。另外,贝叶斯决策论指的就是取后验概率最大时的参数。
用途
两者的用途一致:对参数进行估计!即模型已定,参数未知 。
极大似然估计MLE
$P(样本D|参数\theta)$
核心目标:找到参数θ的一个估计值,使得当前样本出现的可能性最大。
假设有一个样本集合D,且这些样本都是独立的,则参数θ对于数据集D的似然为:
$$P(D|\theta) = P(x1,x2…xn|\theta) = \prod_{x\in{D}}P(x|\theta)$$
由于实际使用中,P(x|θ)往往比较小,连乘容易造成浮点运算下溢,而且为了求导方便,通常使用对数似然(log-likelihood):
$LL(\theta) = log P(D|\theta) = \sum_{x\in{D}} log P(x|\theta)$
此时,参数θ的极大似然估计为:
$\hat\theta = arg_{\theta}maxLL(\theta)$
而这个最大值可以通过求导得出 。
例子
以最为简单的投硬币为例,现在有一个硬币,如果正面朝上记为1,反面朝上记为0,抛10次的结果如下:1111100011=>7正3反。我们的目标就是求出硬币向上的概率。
首先这个问题有10个样本,模型则是二项分布,参数为向上概率θ。
对于每个样本有:$P(x|\theta) = \theta^{x}*(1-\theta)^{1-x}$
那么对于整个数据有似然函数:$P(X|\theta) = \theta^{7}*(1-\theta)^{3}$
最后转为对数似然并求导,令导数为0,可以得到θ=0.7。与我们的预期一致。
极大似然估计的问题: 可以看出通过极大似然估计得到的结果严重依赖于样本,正面向上的概率为0.7与我们的日常经验不符,这就是极大似然的问题所在。
最大后验概率估计(MAP)
极大似然估计的问题就是太依赖样本了,于是最大后验概率估计添加了一项先验概率,可以将其看成惩罚,来平衡由样本得到的概率。
$P(参数\theta|样本D)$
最大后验求的是在样本下,参数θ的最大值。嗯,并不能直观的理解。使用贝叶斯公式转换看看。
★★贝叶斯公式: $P(x|y) = \frac{P(y|x)P(x)}{P(y)}$
转换后:$P(\theta|D) = \frac{P(D|\theta)P(\theta)}{P(D)}$
P(D|θ):似然概率,P(θ):先验概率,P(D):能用全概率公式计算,但不需要,因为我们只关心使值最大的θ,而不是值的本身。
于是求最大后验概率估计变的和求极大似然估计差不多了,就是多了一个先验概率。
例子
任然是刚才的投硬币,我们发现0.7并不符合常识。所以我们加一个先验概率:硬币是正常的,向上的概率符合最大值取在0.5处的Beta分布。 这样再求最大值,θ就会处于0.5~0.7,被修正了。
两者的关系
很明显,最大后验可以认为是极大似然通过先验分布进行了修正。
特别的,可以将极大似然看成先验为均匀分布的最大后验!
特别的,当样本数十分大时,先验概率将几乎没有影响,极大似然的结果与最大后验一致
EM算法
EM(Expectation-Maximization)是常用的估计参数隐变量的利器,是一种迭代式的方法,其基本思想是:若参数Θ已知,则可根据训练数据推断出最优隐变量Z的值(E步);反之,若Z值已知,则可以方便地对参数Θ做极大似然估计(M步)。
在这里只是最最基础的了解,我并不想知道他的推导证明,只想知道他具体是怎么运行的在干什么~感谢文章What is the expectation maximization algorithm?提供的例子!
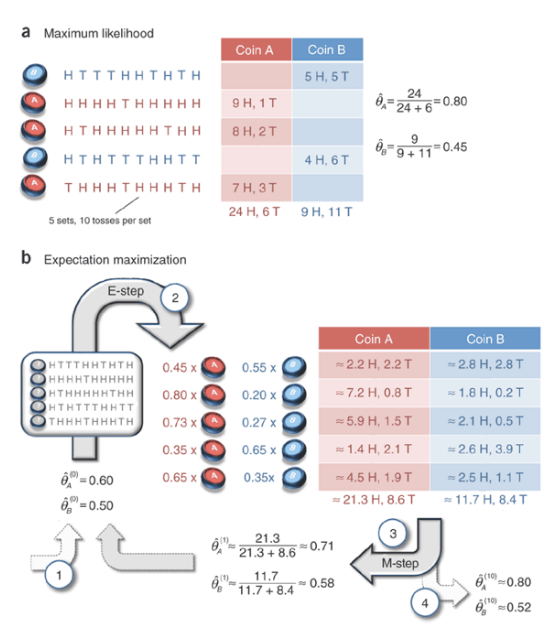
仍然是最常见的投币问题,仍然是估计硬币向上概率。
现在有两枚硬币,我们有其投币后的结果,在一般情况下,我们只要分别计算一下他们各自的最大似然估计就行了,如图a所示。但现在问题来了:如果我们不知道每一次投的是哪一个硬币,即对于每一个样本其“硬币种类”属性是未知的,是隐变量。这个时候我们该怎么求两枚硬币各自的“向上概率”这个参数?
这个隐变量的存在使得问题变得很麻烦,但是EM算法却十分巧妙的解决了这个问题!
● E步(Expectation):基于参数Θ推断隐变量Z的期望。
在这个例子中,我们可以先假设一个Θ。如$\theta_A = 0.6,\theta_B = 0.5$,于是我们可以用这个假设的参数去推断隐变量的期望。
比如对于第一个样本,5正5负,如果是A,其出现概率为$0.6^5*0.4^5$;如果是B,其出现的概率为$0.5^{10}$ 。则期望为:$\frac{0.6^50.\ast4^5}{0.5^{10}} \approx \frac{0.45}{0.55}$ 及0.45的可能为A,0.55的可能为B。
● M步(Maximization):基于观测变量和隐变量的期望Z,对参数Θ做最大似然估计
在E步我们已经获得了隐变量的期望,那么问题就又变的简单了,对参数求最大似然估计即可。如上图所示,我们得到了新的参数$\theta_A\approx0.71,\theta_B\approx0.58$
● EM循环至收敛
接下来要做的就是不断的重复E和M,在数学上可以证明最终会收敛到局部最优解。
其他
还可以将EM算法看作用坐标下降(coordinate descent)法来最大化对数似然下界的过程。
另外,EM算法的思想和以前Google的PageRank的思想可以说十分相似,都是一开始给一个初始值,然后通过不断的自我修正来接近实际值。在PageRank中,网页的得分是根据网页连入量和连入网页质量决定的,也就是说一个网站被别的网站连的越多,且这些网站得分越高,那么这个网站的得分也就越高。但是有个问题,我们并不知道网站的初始得分,且网站得分是由其他网站得分求出的,这就陷入了自己求自己的尴尬问题。和EM算法思想一样,先给所有网站附一个一样的得分,然后不断的用现有得分更新得分,最终获得一个稳定的得分。
模型推断
推断(inference) 是指在观测到部分变量$e={e_1,e_2…e_m}$时,计算其他变量的每个子集$q = {q_1,q_2…q_n}$的后验概率$p(q|e)$ 。设z为其余变量。
根据条件概率定义:$p(q|e) =\frac{p(q,e)}{p(e)}=\frac{\sum_zp(q,e,z)}{\sum_{q,z}p(q,e,z)} $ 。
可以看出,推断问题的关键就是如何高效地计算边际概率分布!
概率图模型的推断可以分为两类:精确推断和近似推断
精确推断
精确推断希望计算出目标变量的边际分布或条件分布的精确值,但由于计算复杂度随着极大团规模的增长呈指数增长,所以适用范围有限。
精确推断实质是动态规划算法,它利用条件独立性来消减计算量。
变量消去
变量消去是最为直观的精确推断算法。
借用西瓜书中的例子:
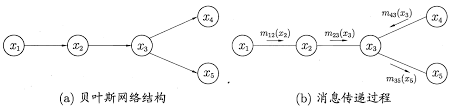
比如我们目标要求边际概率$p(x_5)$
则 $\begin{eqnarray}P(x_5) &=& \sum_{x_4}\sum_{x_3}\sum_{x_2}\sum_{x_1}P(x_1,x_2,x_3,x_4,x_5)\&=&\sum_{x_4}\sum_{x_3}\sum_{x_2}\sum_{x_1}P(x_1)P(x_2|x_1)P(x_3|x_2)P(x_4|x_3)P(x_5|x_3)\end{eqnarray}$
可以看出计算次数为5x1x2x3x4x5。其主要问题是:许多项进行了重复的计算!
那么变量消去的目的就在于避免这种重复计算 。
进行简单的分配可以得到:
$\begin{eqnarray}P(x_5) &=& \sum_{x_3}P(x_5|x_3)\sum_{x_4}P(x_4|x_3)\sum_{x_2}P(x_3|x_2)\sum_{x_1}P(x_1)P(x_2|x1)\ &=& \sum_{x_3}P(x_5|x_3)\sum_{x_4}P(x_4|x_3)\sum_{x_2}P(x_3|x_2)m_{12}(x_2)\ &…&\&=&m_{35}(x_5) \end{eqnarray}$
这个过程可以看成从图的边缘向目标节点出发,逐步求各个节点的边际概率,直到求出目标节点边际概率。
但是单纯的变量消去仍有一个问题:当我们分别求不同节点的边际概率时,需要从头再计算一遍,无疑这又重复计算了。 而信念传播就是用来解决这个问题。
信念传播
信念传播(Belief Propagation)算法将变量消去中的求和操作看作一个消息传递过程。
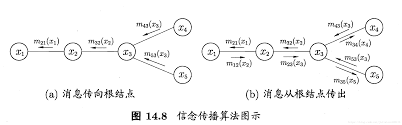
在信念传播算法中,一个节点仅在接收到来自其他所有结点的消息后才能向另一个节点发送消息,且结点的边际分布正比于它所接收的信息的乘积。
这么一来,问题就简单了,对于无环图,信念传播算法经过两个步骤即可完成:
● 指定一个根节点,从所有叶节点开始向根节点传递消息,直到根节点收到所有邻结点的消息。
● 从根结点开始向叶结点传递消息,直到所有叶节点均收到消息。
这样就可以获得所有变量的边际概率 ,而不需要多次计算!
近似推断
精确推断的开销还是太大了,因此现实中一般使用近似推断方法。
近似推断可以分为两类:一.采样sampling,通过使用随机化方法完成近似。
二.使用确定性近似完成近似推断,比如变分推断。
嗯,这部分内容难度有点大,而且我也只是出于了解的目的,所以只写最直观的感受~
基于采样的近似推理
举个简单的例子:给定一个硬币,你如何确定它被抛出后正面朝上的概率?最简单的做法就是抛这个硬币,比如抛 100 次,然后看其中正面朝上多少次。
这是一种用于估计正面朝上的概率的基于采样的算法。对于概率图模型领域内的更复杂的算法,你也可以使用类似的流程。基于采样的算法还可以进一步分为两类。一类中的样本是相互独立,比如上面抛硬币的例子。这些算法被称为蒙特卡洛方法。
对于有很多变量的问题,生成高质量的独立样本是很困难的,因此我们就生成带有依赖关系的样本,也就是说每个新样本都是随机的,但邻近上一个样本 。这种算法被称为马尔可夫链蒙特卡洛(MCMC)方法 ,因为这些样本会形成一个马尔可夫链(Markov chain)。
要详细理解什么是蒙特卡洛,什么是马尔科夫蒙特卡洛MCMC,什么是M-H算法,什么是Gibbs采样,可以看一下Eureka的知乎笔记,其内还有对应的Python实现,还是极好的。
变分法近似推理
变分法近似推理不是使用采样,而是试图通过分析的方式来近似所需的分布。假设你写出了计算相关分布的表达式——不管这个分布是边际概率分布还是后验概率分布。
通常这些表达式里面有求和或积分,要精确评估是极其消耗计算资源的。要近似这些表达式,一种好方法是求解一个替代表达式,并且通过某种方法使该替代表达式接近原来的表达式。这就是变分法背后的基本思想。
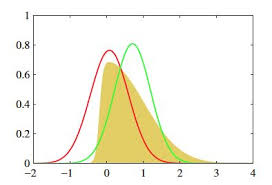
例如:黄色的分布是我们的原始目标p,不好求。它看上去有点像高斯,那我们尝试从高斯分布中找一个红q和一个绿q,分别计算一下p和他们重叠部分面积,选更像p的q作为p的近似分布。这样就从“求分布”的推断问题,变成了“缩小距离”的优化问题。