课程大纲型笔记,查漏补缺型。
个人感觉:必须要先有一定基础,做好章节预习,再看视屏,然后再查资料理解。不然会看的很迷。
2/3.word2vec
one-hot编码:
- 太长,占内存。
- 无法表示词之间的关系(相似性)。
分布相似性(distributional similarity):
- 一种关于词汇语义的理论。
- 通过上下文理解当前词的含义。
分布式表示(distributed representation):
- 用密集向量表示词汇含义。
两个算法:
- Skip-grams(SG):用目标词预测周围词。
- CBOW(Continuous Bag of word ):用周围词预测目标词。
两个训练方法:
- Hieravchical softmax (层次softmax)
- Negative sampling(负采样)
基于统计的方法:
- 直接统计周围词的词频。
- 可以用奇异值分解(SVG)来降维。
- 对高频词比较敏感,需要处理高频词(设置最大值或直接删除等等)。
- 可以根据距离的远近分配权重来计数,也可以通过tf-idf作为权重。
基于统计 vs 基于预测:
- 基于统计:训练速度快。
- 基于预测:能够获得复杂的词相似性,有利于下游的任务。
多义词:
- 能够捕捉到多义词的含义。
- 词向量可以理解为“多义向量的线性叠加”。(比如两百维的向量,可以理解为学习了两百种语义。)
超参数:
- 非对称窗口效果不好。
- 词向量维度取300左右比较好。
- 窗口大小取8左右。
- 数据越多越好,维基百科优于新闻。
GloVe(Global Vectors):
- 结合了统计模型和预测模型。用滑动窗口的形式统计全局特征,效果更好。
杂项:
- Loss function = cost function = objective function
4.word window 分类与神经网络
- softmax
- 最大似然
- 交叉熵和KL散度
- 正则项
- 神经网络的基础推导,反向传导。
- 窗口模型做命名实体识别。
5.反向传播
6.依存分析
Constituency = phrase structure grammar = context-free grammars (CFGs)
短语结构语法 = 无上下文关系语法
语法分析过时了~基本不再使用。难以制定,过于复杂,无法通用…Dependency structure
依存句法结构
通过找到句子中每一个词所依赖的部分来描述句子结构。
依赖模糊 attachment ambiguities
复杂的句子中,依赖关系往往不易确定。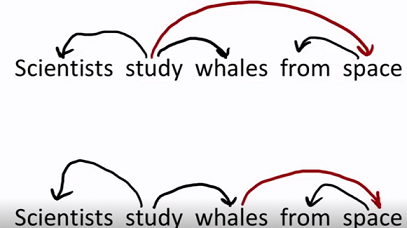
树库 treebanks
一些已经标注好句子依赖关系的数据资源库。- 建立树库是缓慢的
- 可重复利用
- 人们制定的语法往往无法重复使用,因为每个人对语法有自己的理解。
- 许多解析,词性标注等可以基于树库。
- 对于语言学家有利用价值。
- 覆盖更广,而不是像语法那样出于直觉。
- 提供频率和分布信息。
- 能够用于评估系统。

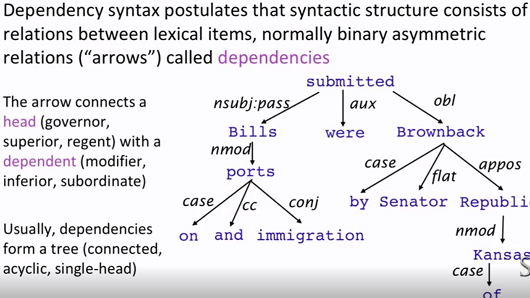
- 依存结构,依存语法
用箭头来表示依存关系。
有一个单独的头部,无环,每个词都有连接。
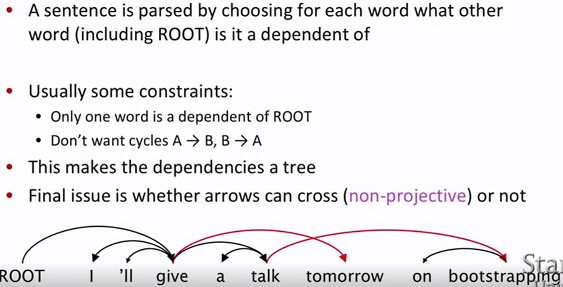
- 投影依存 projective dependency
大部分句子中依存关系是嵌套结构的并有着线性的顺序。也就是说箭头不存在交叉。
- 词序
依存结构无法保存词序(但可以对词加上序号来保留词序)。 - 具体实现方法:
“基于转移的解析”、“确定型依存解析”:机器学习分类问题。

- 基于转移的依存分析
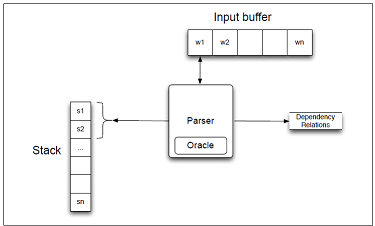
(栈,队列,依存弧)栈:存放待处理的词。队列:从左到右存放单词。依存弧:依存关系(基于语料库)。
3个动作:
● Left-ARC:添加一条s1->s2的依存边,并将s2从栈中删除。即建立右焦点词依存于左焦点词的关系。
● Right-ARC:添加一条s2->s1的依存边,并将s1从栈中删除。即建立左焦点词依存于右焦点词的关系。
● shift:单词出队压入栈。
如果有n种依存关系,则共有2n+1种动作。
注意:得到的序列不一定是唯一正确的。整个分析比较依赖依存关系(语料库)。语料库可以通过treebank转换成我们需要的形式。
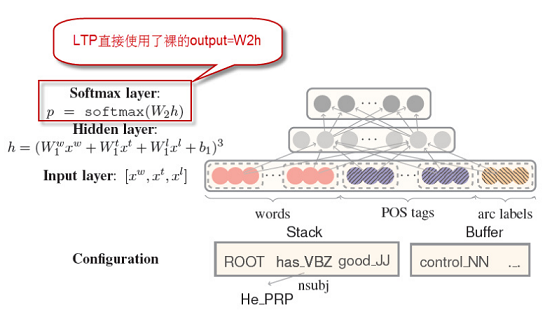
传统的基于转移的依存分析,需要从语料库得到依赖关系。这一步并不是很友好,而使用神经网络可以避免这一步特征提取,大大减少工作量。
<词,词性,依存>做为神经网络的输入。
词:18个单词,用周围词、孩子、孙子来表示当前词。
词性:18个单词所对应的词性。
依存:12个,孩子和孙子的弧标签。
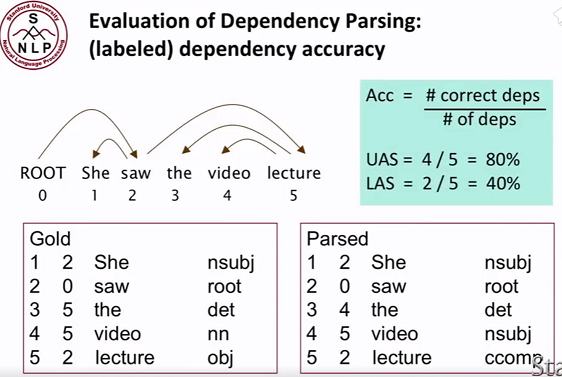
- 评估:
UAS:只关心箭头是否准确。
LAS:还关心标签是否准确。
7.Tensorflow1.x 入门
- 用variables和placeholders构建图,设置loss,选择optimization,将图部署到session(执行环节),session.run。
- tf.variable_scope() tf.get_variable()
- 有点过时了,2.x开启。
8.RNN和语言模型
- 传统语言模型,详见
- RNN
- 梯度消失问题,导致普通RNN无法记忆长序列,一般超过5,6个距离的词对W基本没有影响。

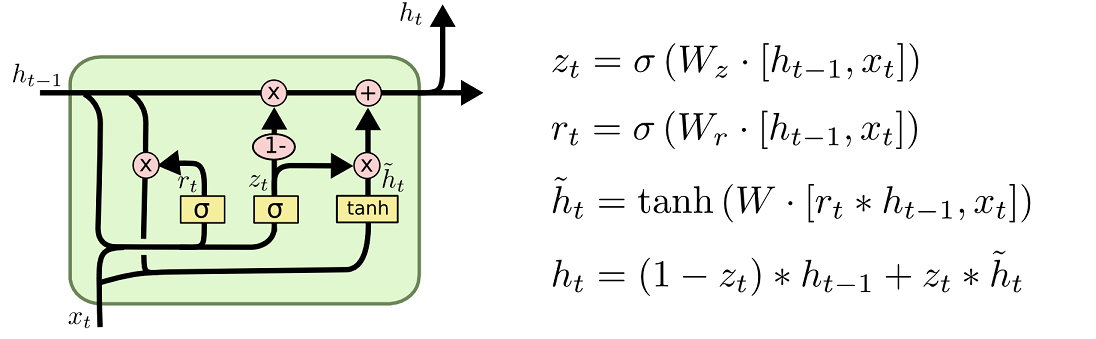
9.LSTM 和 GRU
- seq2seq 模型用于机器翻译
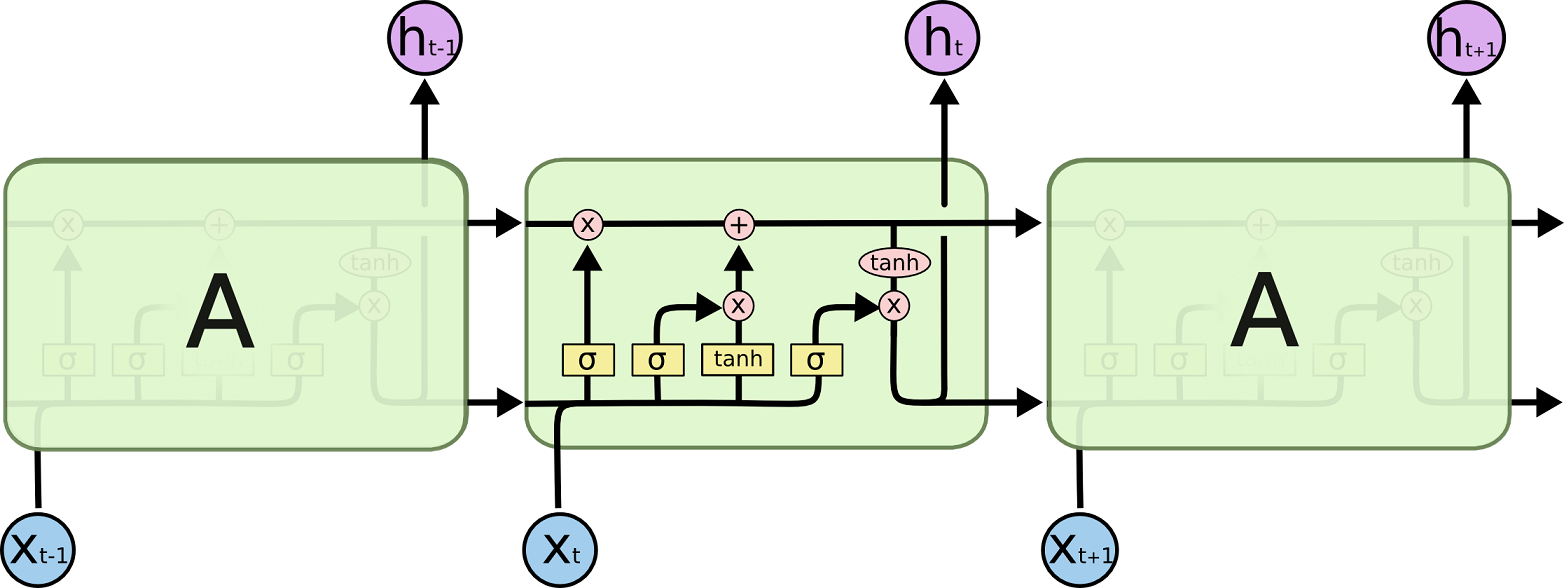
- LSTM
input, output and forget gates
8个矩阵参数

GRU
reset and update gates
3个矩阵参数
注意没有memory cell
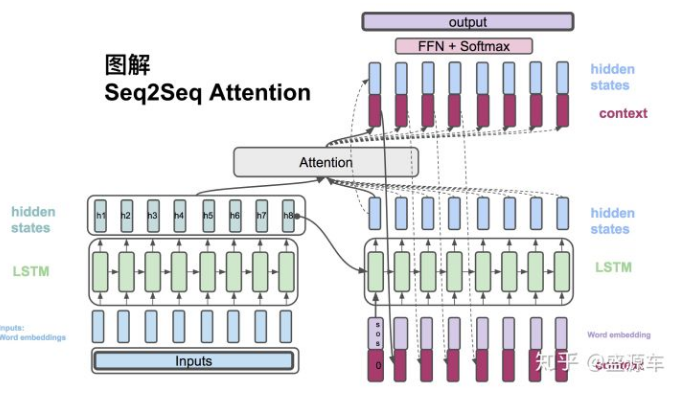
10.机器翻译和注意力模型
- seq2seq模型。
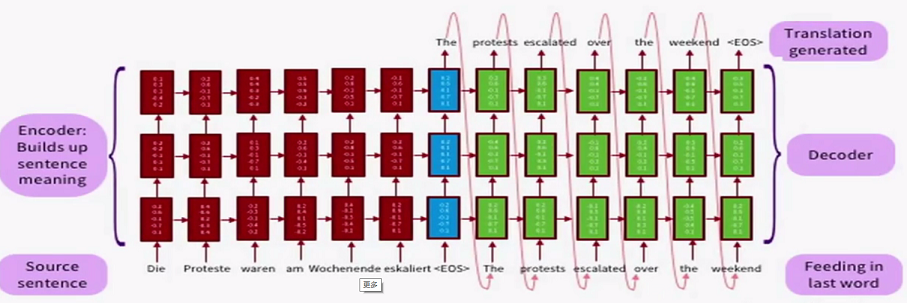
- 神经网络用于翻译的优势:
- 端对端,方便训练。
- 分布式开发。
- 对文本的开发更强。
- 生成的文本更加流畅。

- NMT的缺点:
- 黑盒,不知道内部在干什么。。
- 对句法、语义的使用不够明确。
- 对章节结构、连接子句、回指等高阶的文章概念处理的不好。

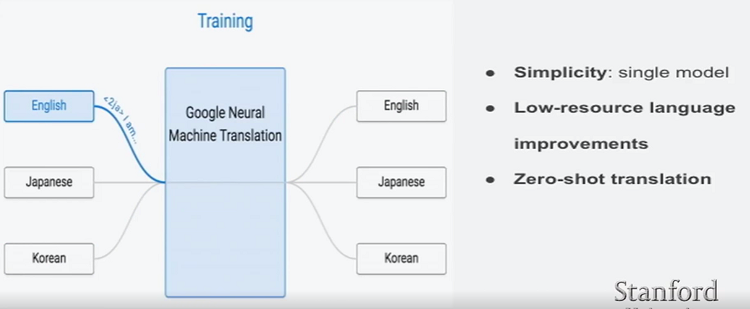
多语言翻译
google非常机智,并没有训练多个模型或者训练多个Encoder、Decoder。而是直接加个标签,表示翻译的目标。

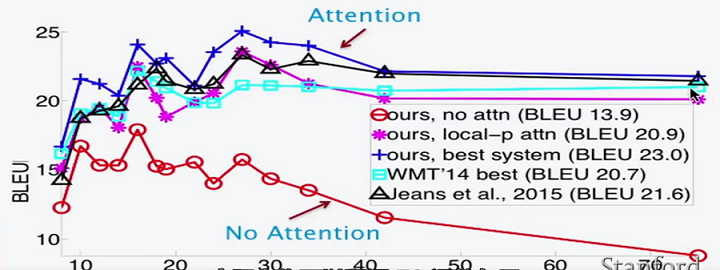
attention vs LSTM
- LSTM只能记住20个词内的信息。而attention没有距离限制。
- 即使在较短的句子翻译中,attention仍然优于LSTM,因为其每个词的翻译更有针对性。
- 对于很短的句子(4,5个词)的翻译,效果都不好。因为太短实际上算不上完整的句子。
attention
11.GRU及NMT的其他议题
!!!为什么LSTM和GRU能够避免梯度消失?
因为这两个网络内部求新的状态矩阵时,都使用了线性相加,而不是矩阵乘法!

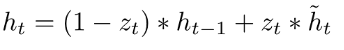
实际上这和残差结构的原理是一样的!误差传递时,两项相加能够一定程度的防止梯度消失,但并不能规避梯度消失,只能缓解(从6个左右增长到了20个左右)。
使用建议
dropout一般用于垂直网络,水平网络(RNN)一般不用(需要特殊处理)。

集成能够有效的提高最终结果。比如训练10个网络求平均。
Softmax非常的占训练时间,比如Google翻译网络训练时有将近一半的时间用在计算softmax!
- Hierarchical softma,层次softmax。但对GPU不友好。
- 负采样
12.语音处理的端对端模型
简单略过。。
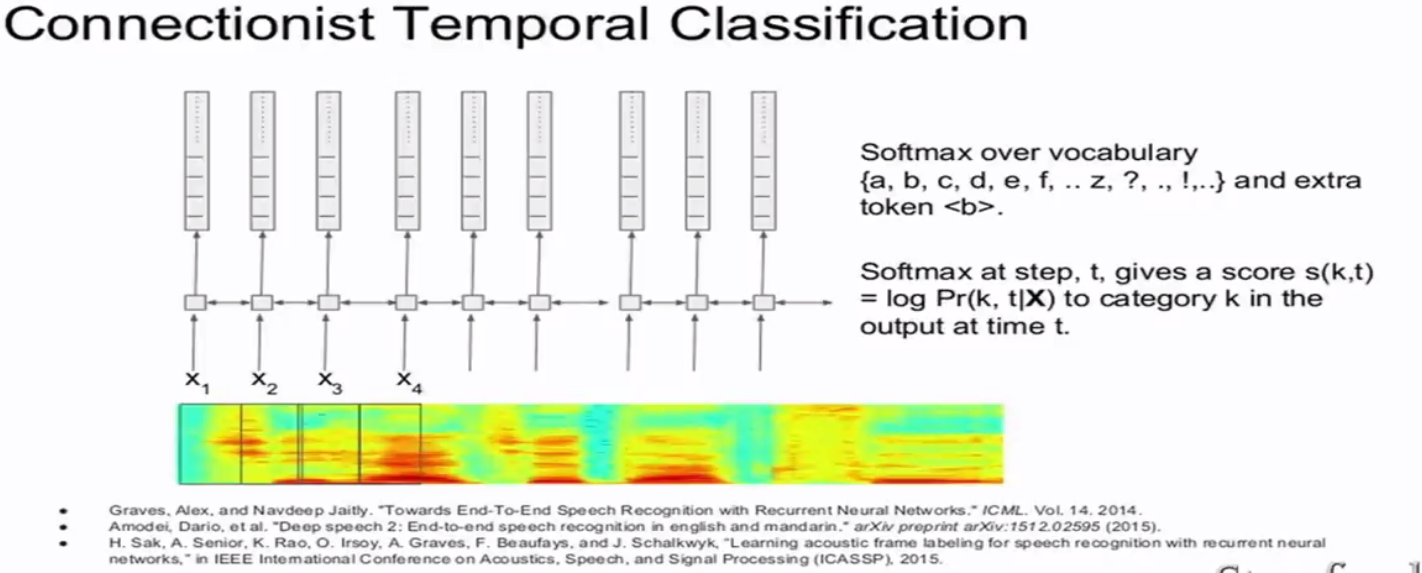
- 连接时序分类法(CTC,Connectionist Temporal Classification)
seq2seq with attention
每次预测都使用整个输入,用yi-1预测yi。对于很长的语音效果会不好(定位难度会加大)。
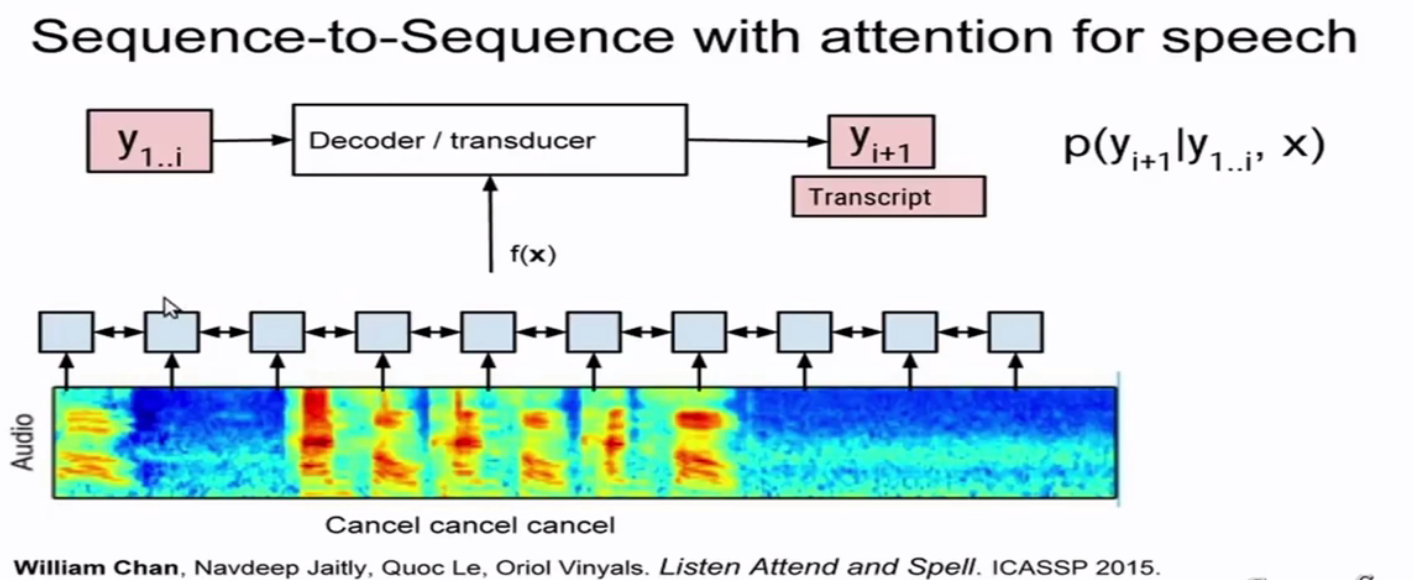
LAS(Listen and Spell)
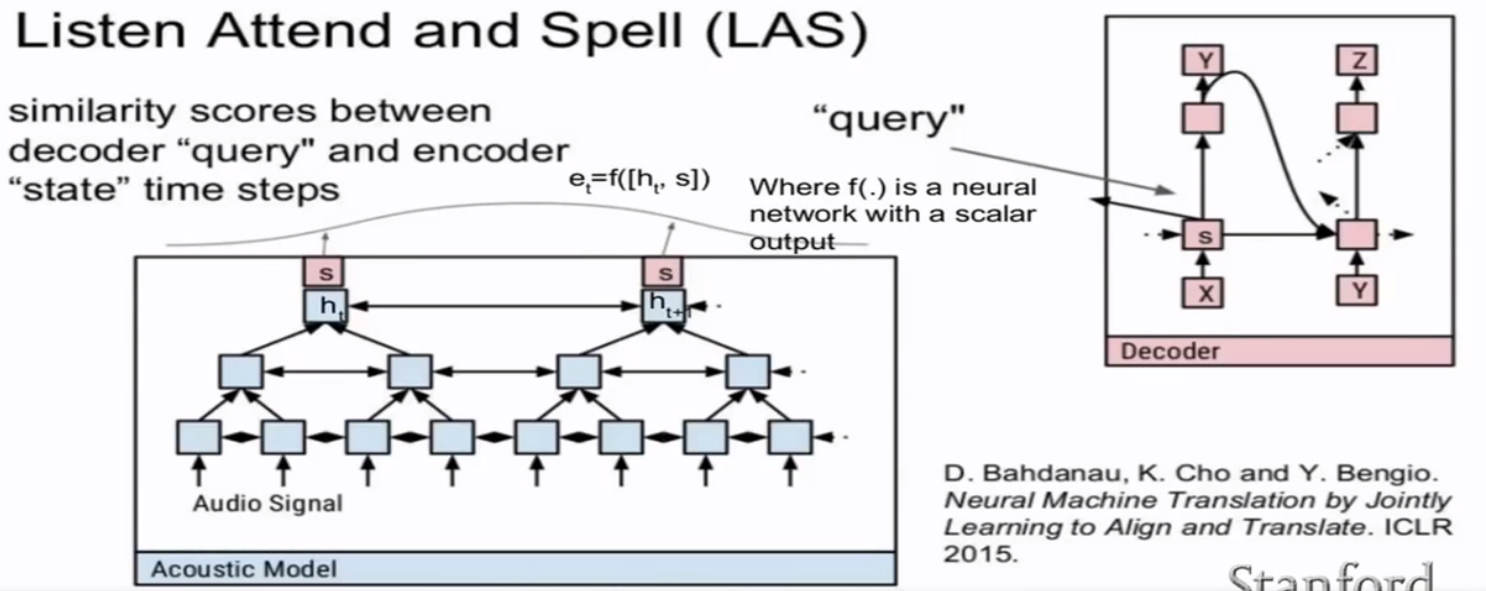
- 输出根据整个输入,导致需要输入完全后才能处理。
- attention计算的瓶颈,序列越长,学习越困难。
- 输入的长度对准确率有很大影响。

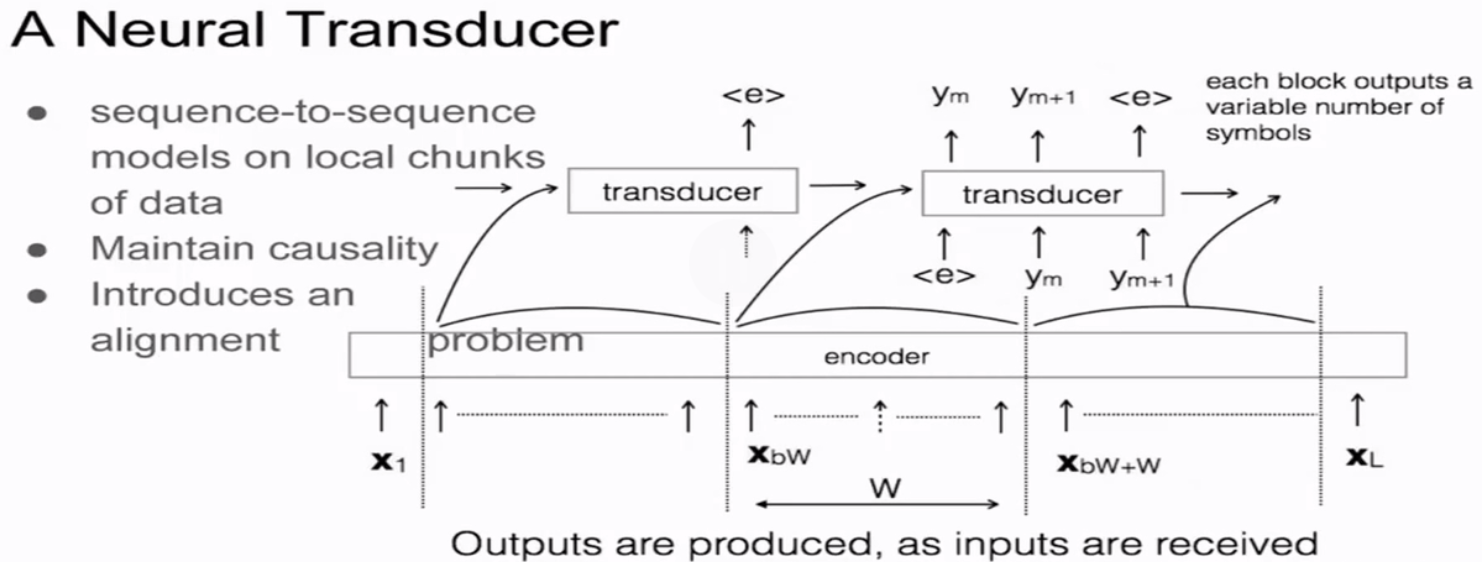
online sequence to sequence Model
将输入切成一个个的小时间块,每次只识别一个时间块的内容。
13.卷积神经网络
???不知道为什么这章取名为卷积神经网络。。。。。明明就介绍了一个问答模型。
- Dynamic Memory NetWork(DMN)
- 问答系统
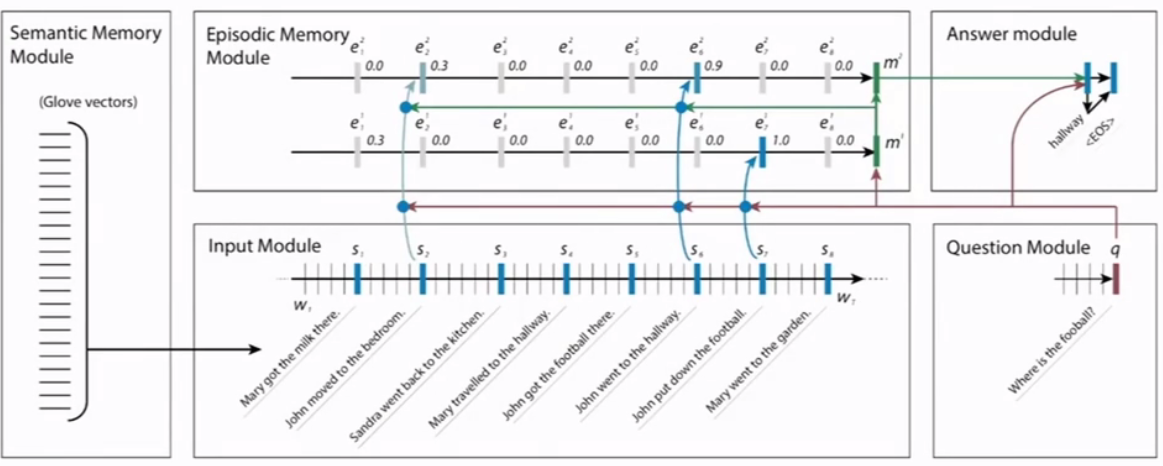

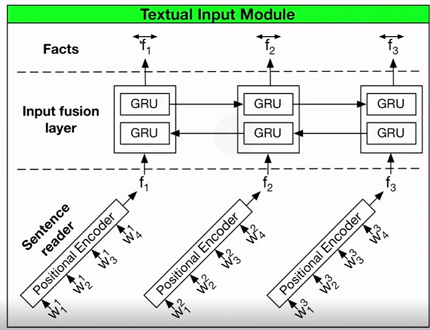
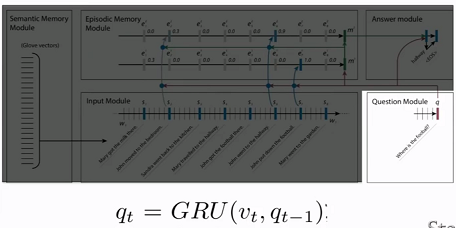

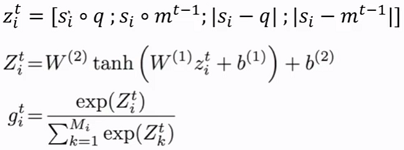
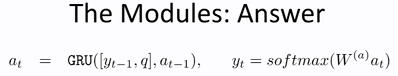
处理图片数据
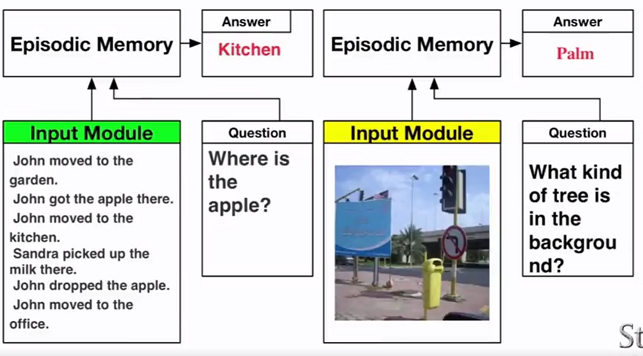
14.tree RNN 和 短语句法分析
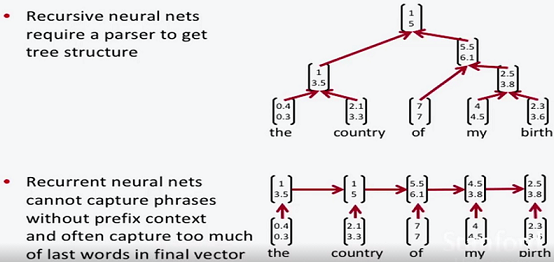
递归神经网络 vs 循环神经网络(tree RNN vs RNN)
递归神经网络对短语的抓取能力更强。向量相近的短语可以认为意思相近,这样能够获得更多有意思的结果。
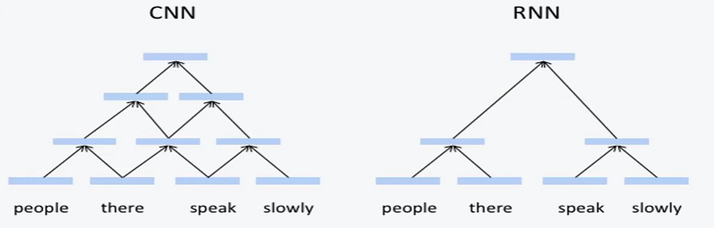
tree RNN vs CNN
- CNN会抓取所有可能的短语。而tree RNN只抓取有一定语法的短语。
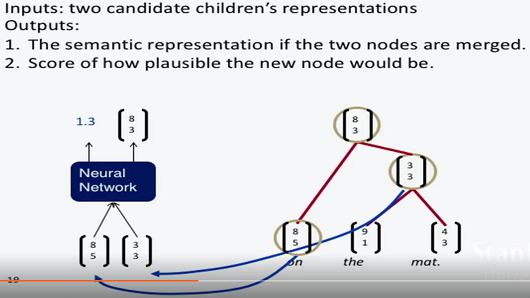
递归神经网络结构
- 输入就是两个子向量。
- 输出一个向量和一个可能性得分。根据得分情况判断是否进行合并。
- 具体实现可以用贪心策略,每次合并得分最高的节点。
- 最后整棵树的得分可以用各个节点的得分和表示。并将其作为网络优化目标。
- 特殊的反向传播技巧:贯穿结构反向传播(through structure)。
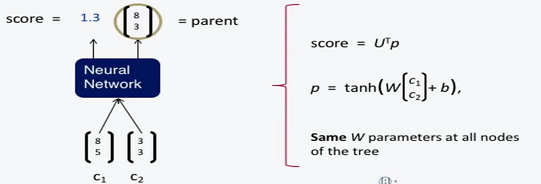
基础TreeRNN存在的问题:
- 只用一个矩阵无法获取复杂的语法关系。
- 两个输入节点之间没有产生关联。

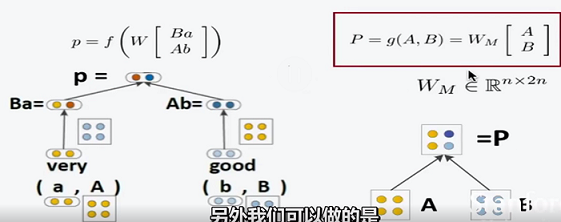
TreeRNN改进方法:
- 简单来说就是不在共用一个矩阵,对不同类型的输入情况使用对应的矩阵(比如名词+形容词矩阵、名词+动词矩阵等等)。

- MV TreeRNN(Matrix-Vector model)
- 对各种情况设置矩阵并不容易。
- 每个节点都有 一个向量和矩阵,交换相乘来获得新的向量,这样一来词之间就有了交互,并自带了词性等信息。
- 缺点在于要训练太多矩阵,参数训练太困难。另外,矩阵构建也困难。
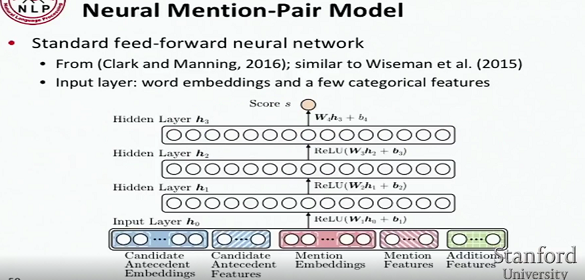
15.共指解析 Coreference resolution

- 排名模型:对候选先行词进行逐个词打分,取最大得分。

- 提及匹配模型
16. 用于问答的动态神经网络
- 略过
17. NLP的问题和可能性架构
略过
18. NLP局限性
- 多任务
- 介绍自己的模型。略过。。。