1. 医疗隐私泄露
医疗数据泄露一直是一个比较严重的问题,因为医疗数据中往往包含着非常非常隐私的个人信息,所以相比于其他数据的泄露,医疗数据的泄露后果更加的严重。
下面是近几年比较大的几次医疗数据泄露事件:
● Verizon发布的《2015 Protected Health Data Breach Report》中显示25个国家共1931次已确认的健康数据泄露事件和超过39.2亿条医疗信息泄露。
● 美国,2015年5月,BCBS旗下的CareFirst保险公司1100万用户信息因黑客攻击泄露;2015年9月,Excellus保险公司因黑客入侵近千万用户信息泄露。
● 中国,2016年7月,30个省份至少275位艾滋病感染者个人信息泄露。
● 在乌克兰,2016年8月,乌克兰黑客组织“PRAVYY SECTOR”入侵COUG(俄亥俄州中部泌尿外科集团)的服务器并获得223G重要数据,泄露的40多万份文件中包含大量隐私数据。
● 2017年10月11日,安全研究机构KromtechSecurity Researchers披露,一家医疗服务机构存储在亚马逊S3 上的大约47GB医疗数据意外对公众开放,其中包含 315363 份PDF文件,15万病人信息。
● ……
医疗隐私的泄露会使的群众对于自身信息的安全性感到怀疑,从而变的不愿意共享自身的医疗信息用于研究。美国的一项调查发现,59%的患者认为EMR / EHR系统的广泛应用会导致更多的个人信息丢失或被盗,而51%的人认为目前健康信息的隐私未充分保护[9]。这种情况无疑会对医疗数据的使用带来巨大的阻碍。
2. 医疗隐私攻击
可能有人会觉的医疗数据的泄露方式比较单一,因为从上面列举的案件中不难发现大部分的医疗数据泄露都与黑客攻击有关,这使得医疗数据泄露问题更像是计算机安全问题。但事实上并不是这样,之所以列举的案件很多都是黑客攻击,是因为这种攻击方式最容易被发现,且一次性的破坏能力最大,而实际中更多的攻击却是无声无息的,更具有目标性的,是基于数据推断的。
数据推断攻击根据攻击的程度可以分为以下三类:
● 身份披露:能够重新识别该主体。
● 属性披露:无法重新识别该主体,但是能够推断出该主体的一些信息(如当属性取值单一时)。
● 成员披露:能够确定该主体在数据集中(较弱,但当数据集比较特殊如艾滋病数据集时会变为属性披露)。
那么接下来本节将依次介绍几种最为常见的医疗数据推断攻击。
2.1 链式攻击[1]

链式攻击指的是将多份公开发布的数据表(这些数据表往往是独立的、安全的)进行链接匹配,从而重新识别个人。
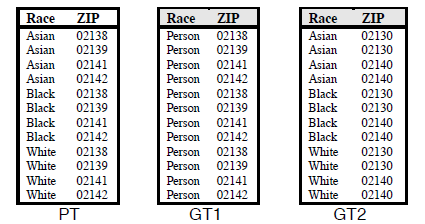
比如在美国,全国卫生数据组织协会(National Association of Health Data Organizations,NAHDO)推荐各州收集包含<邮编,生日,性别>的数据[2]。保险组织( Group Insurance Commission,GIC)认为包含这些属性的信息是安全的,将其提供给工业界(图一左)[3]。而人们可以很轻松的得到选民登记信息(图一右)[4] 。两张表进行结合对比可以确定大量的个人隐私信息。
在1990年,有一个广为人知的对于一个索赔数据库进行链式攻击的案例。案例中保险委员会发布了一份包含135000名病人的资料。攻击者则花费了20美元购买了一份剑桥选民登记清单,通过对两份数据的链接攻击者成功的识别了马萨诸塞州州长的出院记录。
链式攻击可以说是最为简单,成本最低的攻击了。其主要原因是发布的数据表单忽视了“准标识符”的重要性。
2.2 同质性攻击[5]
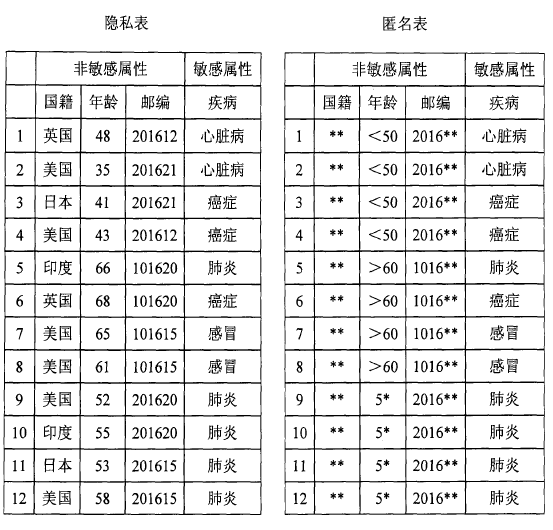
假设A和B是关系不和的邻居。有一天,A生病了被救护车送到医院。由于看到了救护车,B发现A可能得了某种疾病。后来B发现了被医院公开发布的关于病人记录的匿名表(右图),根据时间他知道在表中的记录当中某一个是A的数据。由于是A的邻居,他知道A是一个56岁的美国人,性别男,居住地的邮政编码是201615。因此,B知道A的记录数据是9,10,11,12之一。由于,所有的病人都得的是同样的疾病肺炎,所以得出A得了肺炎。
可能你会觉的这种攻击的可能性不大,但事实上这种情况并不罕见。作一个包络计算,假设我们有一个包60,000个不同元组的数据集,其中敏感属性可以取3个不同的值,并且与不敏感属性不相关。对这个表进行5-匿名化(指拥有相同非敏感属性的元组数大于5,具体请看“K-匿名法”)将会有大约12000个组。平均而言,每81个组中将有1个没有多样性(敏感属性的值都是相同的)。因此,我们应该会得到大约148个没有多样性的群体。因此,大约会有740人的信息会受到同质性攻击的影响!
同质性攻击的发生是由于发布的数据表单中敏感属性缺乏多样性。
2.3 背景知识攻击[5]
背景知识攻击与同质性攻击比较相似,但攻击者拥有一些患者或敏感属性的背景知识,这使得背景知识攻击更容易推断出患者的隐私信息。
仍然是A和B,B知道A去了一家医院,A的病历表出现在匿名表中(右图)。现B知道A是一个41岁的日本女人,住的地方的邮编是201621。根据上面的信息,知道的信息包含在记录1,2,3,4里面。如果没有额外的信息,是不能确定A是患的心脏病还是癌症。然而,众所周知日本人患心脏病的概率是相当低的。因此,得出结论几乎可以肯定患了癌症。这一种是对于敏感信息的背景知识攻击。
还有一种情况是对普通信息的背景知识攻击。A知道B在一次购物中购买了牛奶,啤酒和尿不湿。然后将这个组合信息与公布的消费数据进行比对。通过这种方法A可以得到很小集合的数据甚至能够确定唯一数据,那么A就可以得到B的其他购物隐私信息比如药物。
还有一种情况是从外部环境中获得背景知识,比如报纸等。

如图所示,报纸往往会比较详细的报道一个人发生的事情比如出车祸,而通过这些详细信息往往就能很容易的确定一个人的医疗记录。
2.4 无序匹配攻击[1]
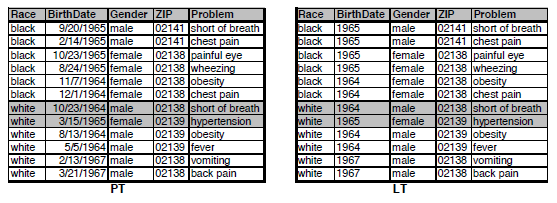
医疗数据实际使用中,往往会对一张表进行多次发布,如果两次发布的数据不变,只是匿名方法发生改变,可能会导致两张表能够按照顺序进行匹配造成隐私泄露。如上图所示,由于数据顺序未变,因此可以轻易的由GT1和GT2表得到PT表。
对于这种攻击方式只需每次发布时打乱组元的顺序即可。
2.5 互补发布攻击[1]
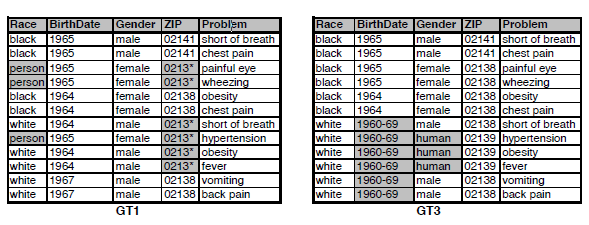
事实上就算将两次发布的数据顺序进行了打乱,仍然有可能出现隐私泄露问题。如将表PT进行匿名化处理,可能会得到表GT1和表GT3两种处理结果,这两张表都是安全的,但是如果这两张表都进行了发布。那么攻击者就可以通过{problem}属性连接两张表从而得到表LT。而表LT中的某些元祖是唯一的,是不安全的。
对于互补发布攻击的预防措施一般有两种:1.将所有的属性作为准标识符进行处理。2.后面发布的表都在前表的基础上进行匿名化(如GT3基于GT1进行匿名化)。
2.6 时序推理攻击[1]
时序推理攻击与互补攻击比较相似。因为实际使用中的数据是动态的,组元会增加,改变,移除。这些变化会导致表的匿名结果出现变化(如2.5图中当PT表第一次发布的匿名表为GT1,后PT表增加 [ black, 1965, male, 02139, headache]组元,再次发布时由于组元变化匿名表变为GT3形式,两表通过{problem}连接可得出表LT)。
对于时序推理攻击的预防方式与预防互补攻击的方式相同。
2.7 多次查询推理[6,7,8]
现在许多医疗数据平台允许使用者每次可以查询少量的医疗数据。往往这些数据单独使用不会造成隐私泄露,但攻击者可以通过对一个数据库的多次查询得到个人隐私信息。比如数据库存在表{医生,病人,药物},数据库允许一次少量查询{医生,病人}信息和{医生,药物}信息,因为少量的这两类信息都是安全的,但通过多次查询可以推断出{病人,药物}信息,这个信息则是危险的因为药物往往可以看出病情。
对于多次查询推理攻击,一般通过限制访问次数来防止这类隐私泄露,但如果事先匿名数据,通常反而能保留更多的信息。
3. 总结
这些攻击方式比起强硬的黑客入侵式攻击更为的恐怖,更难防范。因为对于黑客攻击,防范的方式比较明确:增强网络安全,权限控制等。而这些攻击方式往往能做到在毫无觉察的情况下,隐私就遭到了泄露。这使得医疗数据的公开使用、共享变的困难重重。
当然攻击方式并不只有以上几种,以上只是几种最著名的攻击方式。事实上,每当有新的数据保护方法提出时,作者会相应的提出这种方法解决的问题,而这个问题往往就是一种新的在某种情况下的数据攻击方式~
参考文献
[1] L. Sweeney. K-anonymity: A model for protecting privacy. Int. J. Uncertain. Fuzz., 10(5):557-570, 2002.
[2] National Association of Health Data Organizations, A Guide to State-Level Ambulatory Care Data Collection Activities (Falls Church: National Association of Health Data Organizations, Oct. 1996)
[3] Group Insurance Commission testimony before the Massachusetts Health Care Committee. See Session of the Joint Committee on Health Care, Massachusetts State Legislature, (March 19, 1997).
[4] Cambridge Voters List Database. City of Cambridge, Massachusetts. Cambridge:February 1997.
[5] A. Machanavajjhala, J. Gehrke, D. Kifer, and M. Venkitasubramaniam. ℓ-diversity: Privacy beyond k-anonymity. In Proc. 22nd Intnl. Conf. Data Engg. (ICDE), page 24, 2006.
[6] D. Denning. Cryptography and Data Security. Addison-Wesley, 1982.
[7] D. Denning, P. Denning, and M. Schwartz. The tracker: A threat to statistical database security. ACM Trans. on Database Systems, 4(1):76–96, March 1979.
[8] G. Duncan and S. Mukherjee. Microdata disclosure limitation in statistical databases: query size and random sample query control. In Proc. of the 1991 IEEE Symposium on Research in Security and Privacy, May 20-22, Oakland, California. 1991.
[9] National partnership for women & families, making it meaningful: how consumers value and trust health it survey. http://www.nationalpartnership.org/ (2015). Accessed 6 Sept 2015