主要参考天空的城和范永勇的学习路线,对于RE有了基本的认知。
基本分类
● 基于规则的模式匹配(Using Hand-built Patterns)
比如,对于IS-A这样的关系,我们可以使用如下的规则进行抽取:
1 | “Y such as X ((, X)* (, and|or) X)”! |
除了这种基于简单句法结构的规则,我们还可以借助实体识别(Named Entity tags)来帮助我们进行关系抽取:
1 | located-in (ORGANIZATION, LOCATION) |
把基于字符串的 pattern 和基于 NER 的 pattern 结合起来:
1 | PERSON, POSITION of ORG |
优点:
- 人工规则有高准确率(high-precision)
- 可以为特定领域定制(tailor)
- 在小规模数据集上容易实现,构建简单。
缺点:
- 低召回率(low-recall)
- 特定领域的模板需要专家构建,要考虑周全所有可能的 pattern 很难,也很费时间精力
- 需要为每条关系来定义 pattern
- 难以维护
- 可移植性差
● 基于监督学习的方法(Supervised Method)
我们可以把关系抽取当成一个多分类问题,每一种关系都是一个类别,通过对标签数据的学习训练出一个分类器(classifier)即可。主要难点有两个:
- 特征构建
传统的基于机器学习的方法会使用一些NLP技术构建组合特征,比如词性标注,依存分析等。

标签数据的获取
监督学习的效果直接取决于训练数据集的大小和质量,但是获得大量的标注数据的代价是非常昂贵的。
● 半监督学习方法(Semi-supervised)
半监督学习主要是利用少量的标注信息进行学习,这方面的工作主要是基于 Bootstrap 的方法以及远程监督方法。
基于种子的启发式算法(Seed-based or bootstrapping approach)
[Hearst et al. 1992] Automatic acquisition of hyponyms from large text corpora.具体步骤:1.我们先准备一些准确率很高的种子实体-关系组。2.以这些种子实例为基础,去语料库里找出所有相关的句子。3.对这些句子的上下文进行分析,找出一些可靠的pattern。4.然后再通过这些pattern去发现更多的实例。5.通过新的实例再去发掘出新的pattern,如此往复,直到收敛。
结果是获得大量的pattern。

优点:
构建成本低,适合大规模构建
可以发现新的关系(隐含的)
缺点:
对初始给定的种子集敏感
- 存在语义漂移问题
- 结果准确率较低
- 缺乏对每一个结果的置信度的计算
远程监督学习(Distant Supervision)
[Mintz et al.2009] Distant supervision for relation extraction without labeled data基本假设:两个实体如果在知识库中存在某种关系,则包含该两个实体的非结构化句子均能表示出这种关系。
具体步骤:
- 从知识库中抽取存在关系的实体对
- 从非结构化文本中抽取含有实体对的句子作为训练样例,然后提取特征训练分类器。
结果是获得一个分类器。

结合了 bootstrapping 和监督学习的长处,使用一个大的 corpus 来得到海量的 seed example,然后从这些 example 中创建特征,最后与有监督的分类器相结合。与监督学习相似的是这种方法用大量特征训练了分类器,通过已有的知识进行监督,不需要用迭代的方法来扩充 pattern。与无监督学习相似的是这种方法采用了大量没有标注的数据,对训练语料库中的 genre 并不敏感,适合泛化。
缺点:
- 假设并不一定成立,实体之间往往存在多种关系,会出现很多错误标签。
- 基于手动的特征工程效率不高,Mintz的文章,在获得标签数据后,会根据句子出现的频率构建一组特征,然后去训练一个分类器。这些特征大多是基于NLP技术的,比如词性标注,句法解析等。我们知道这些NLP技术还不是特别完美,会出现大量错误,而这些错误会在关系抽取系统累积传播,从而影响最终的分类效果。
● 无监督学习(unsupervised)
无监督学习一般利用语料中存在的大量冗余信息做聚类,在聚类结果的基础上给定关系,但由于聚类方法本身就存在难以描述关系和低频实例召回率低的问题,因此无监督学习一般难以得很好的抽取效果。
监督学习
常用数据集SemEval 2010 Task 8:其中第一行为sentence,第二行为两个entity的relation,第三行为备注。
1 | The <e1>microphone</e1> converts sound into an electrical <e2>signal</e2>. |
1. Simple CNN Model (Liu 2013)
Liu,(2013). Convolution neural network for relation extraction. 8347 LNAI(PART 2), 231–242.
在这篇文章之前大部分RE关注于语法关系,使用语法树、依存树等方法。构建树非常耗时,不论是训练阶段还是预测阶段,而且手工构建特征也很麻烦。
这篇文章应该是第一次使用CNN来做关系分类任务,其靠CNN来获取局部语法学习。
CNN简介:CNN就像是N-gram的简化版。在NLP中CNN的卷积核的长度是固定的(就是向量的长度),能变化的是核的宽度(一次扫多少词N)、核的深度(核的个数)以及步长(每次扫描后移动的距离)。不同宽度的核能够学习不同大小区域的局部关系,步长则决定了卷积核输出维度的大小。实际上,每个卷积核能各自学习某一些特征。一般CNN都有一个Pooling层,其目的有两个:1.固定输出维度,因为不同的核输出维度可能不一样,如果不池化后续处理比较麻烦。2.降维,只保存重要信息,减少计算量。最常见的池化方式是Maxpool,即只保留最大值,当然还有许多其他十分有用的池化方式。
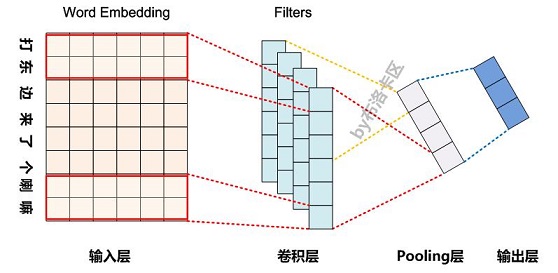
- 模型输入
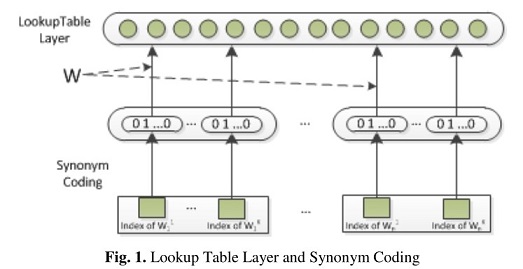
模型的核型输入:synonym list。同义词词典通过Wordnet构建,将同义词归为同一个簇,如果某个词没有同义词,则单独一个类别。一个单词通过查表可以获得一个one-hot编码。
其他输入:根据实际情况可以添加特征,比如:word list,POS lsit,mention level list,entity major type list,entity subtype lsit。
Lookup Table:简单来说就是一个用于降维的矩阵,类似embedding层。
模型
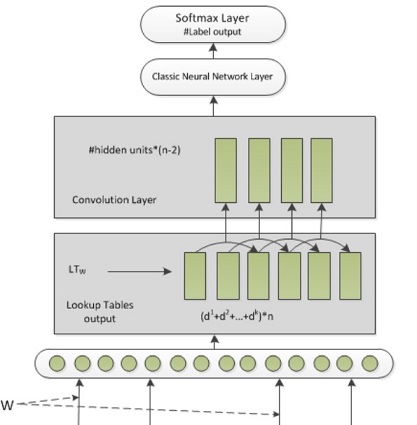
整个模型十分简单,输入层+卷积层+(pooling层,图中未表示)+全连接层+softmax。
$k:特征数。d^k:特征维度。n:字数。hidden-units:核数。$
Classic Neural Network-Layer:先通过“MAX Layer”,也就是Max pooling,再进行全连接降维到分类个数。
Softmax Layer:常规的log-likelihood。
- 实验
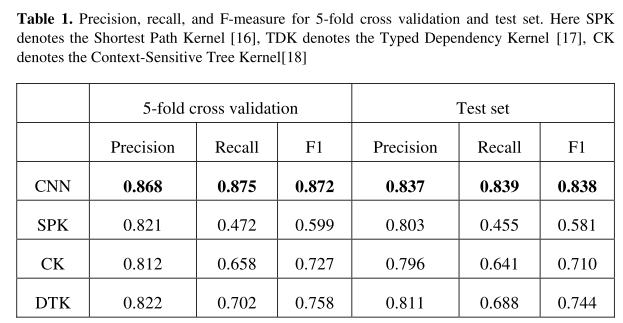
可以看到Recall的提升非常的明显。比传统的语法模型,泛化能力强很多。
总结
优点:
- 使用CNN来提取语法结构,既方便,效果还好。
- 使用Synonym list,相当于引入额外的信息,效果有提升。
缺点:
- 仍然使用了预训练的NLP特征,会存在误差传播的问题。
- Synonym Endedding不足以表示语义信息,后续工作都会加入pre-train的word embedding。
- 为了统一训练句子的长度(顺便还能提供实体位置信息),使用了window size,即使用两个实体周围的固定个数的词。实际上从训练效果来看这个值越大越好,Windows size的存在可能会造成信息的损失。
2. CNN without NLP tools to extract features(Zeng 2014)
Zeng, . (2014). Relation Classification via Convolutional Deep Neural Network. Coling, 2335–2344
之前那篇文章虽然使用了CNN提取特征,放弃了语法树,但是仍然借助NLP工具获得特征,比如POS,entity type等。但是用现成的NLP工具获取这些特征是存在错误的,而这个错误会传播到之后的网络中。
这篇文章最重要的改进就是开始靠自己提取语法特征(虽然不完全),并使用了word embedding、position feature等优秀的策略。
- 模型框架
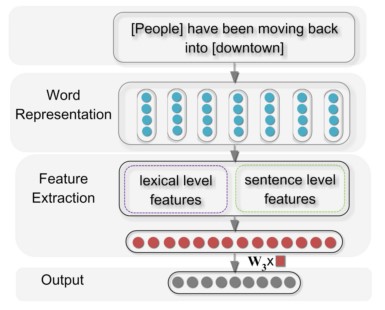
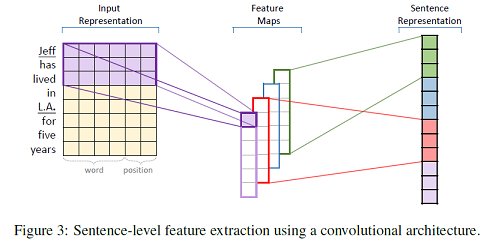
整体框架非常清楚,先对文本进行word embedding,然后提取特征,这一步分成了字符级的特征和句子级的特征,最后softmax。
字符级特征
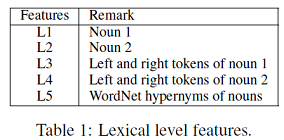
- L1: entity1
- L2: entity2
- L3: entity1的左右两个tokens
- L4: entity2的左右两个tokens
- L5: WordNet中两个entity的上位词
将这5个特征连接在一起作为字符级的特征。
句子级特征
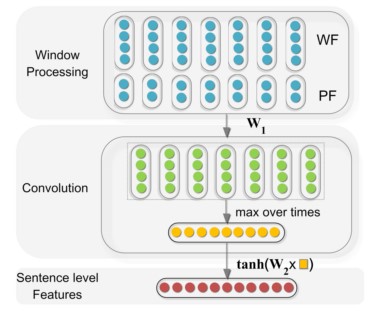
在卷积之前先对词向量做了预处理。
word feature:
这一步的处理十分奇怪,在这一步定义了一个w(windows)变量,将范围内的词向量进行了合并。
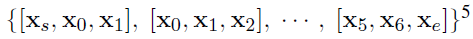
实际上就是定义了卷积核的宽度。。。
position feature:
这一步比较巧妙,用跟两个实体的相对距离[d1,d2]来添加位置关系。

Convolution:
进行卷积操作,由于在word feature中进行了临近向量的合并,所以在这里做卷积不需要卷积核的移位,直接矩阵相乘就完事了。做完卷积后也没有经过激活函数,直接进行了max polling。
Sentence level feature:
对卷积结果做一个全连接+tanh激活,就得到了句子级别的特征。
实验结果
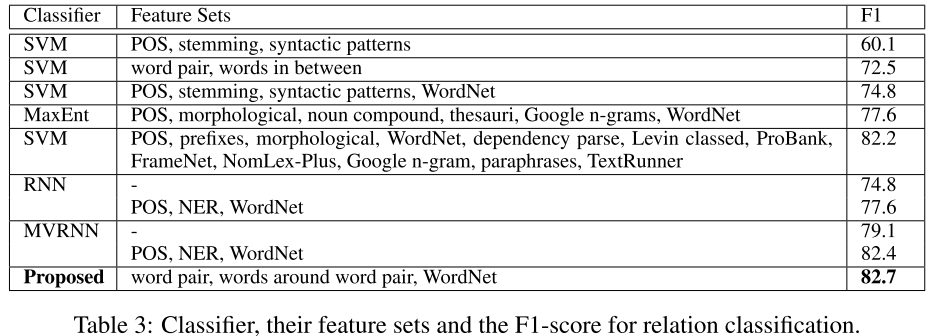
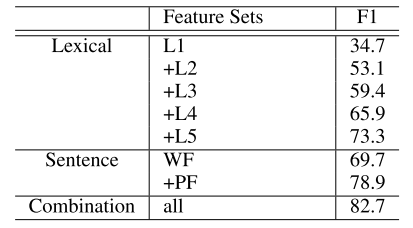
结果如图,各个部分对结果的提升都有一定的帮助。
总结
优点:
- 引入了位置信息,CNN关心的是局部N-gram特征,特别在max pooling时不关心位置信息,这对于文本是不利。因此加入位置特征,使得与实体的位置远近也会对卷积结果造成影响。
- 做到了端到端模型,不用借助其他NLP特征。
缺点:
- 只有一个window size,提取的特征会比较单一。
- 还是有人为构造的lexical feature,实际上这个特征是能够通过网络学习到的。
3. CNN with multi-sized window kernels(Nguyen 2015)
这篇文章方法非常非常的清晰,尽可能抛弃了外来特征,只用了词嵌入和位置特征。使用多尺寸的卷积核来提取n-gram特征,可以认为强行用卷积核学习到了之前的Lexical feature。
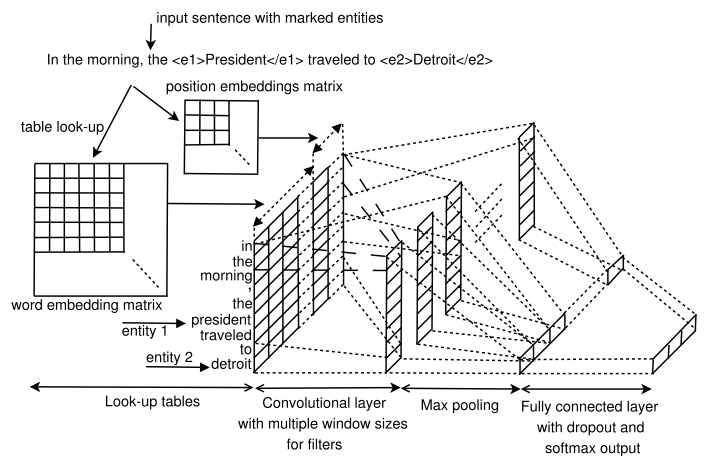
模型结构
- 输入:词用预训练word embedding;位置信息专门训练一个矩阵将 [i-i1,i-i2]进行映射。将两者连接作为输入向量。
- 卷积层:采用多个尺寸的卷积核进行卷积操作,并进行了tanh变换。
- 池化层:采用max pooling。
- 全连接层:全连接+dropout+softmax。
实验
- ACE 2005 训练结果
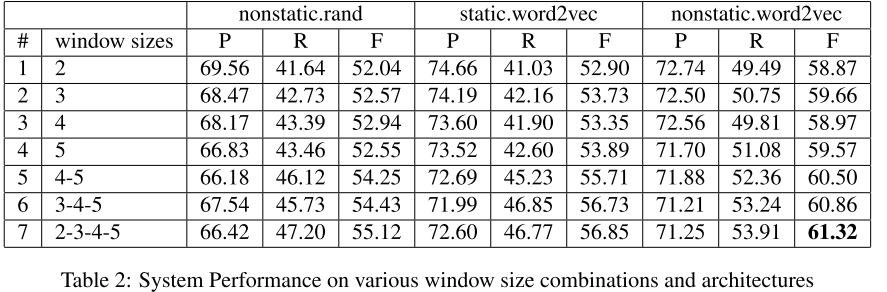
测试了不同窗口尺寸和词向量矩阵是否训练的结果。
可以看到:
不同尺寸的卷积核都使用效果是最好的,其中4大小的卷积核能学到的东西最多。
将词向量矩阵设置为可训练能获得最好的成绩。semEval 训练结果。

嗯。可以说效果和最好的模型持平,并没有多大的提升。
Relation Classification VS Relation Extraction
可能会奇怪,上面两个数据集跑出来的结果怎么会差这么多?这里文章提到了关系分类和关系提取的区别: 关系分类的数据往往是均衡的,各个关系类别的数量相差不大。而关系提取的数据往往不均衡,一般“无关系”这个类别占大多数。
semEval直接提供一个句子中的两个实体以及其关系,对于ACE作者则是将句子中的实体进行了两两组合其中大部分实体是无关系的。
从下表可以看出,能确定分类的关系比重越大F值就越大。但可惜的是实际场景中一般都是关系提取,所以现实的效果会比较差。而关系分类一般都是实验场景。
总结
优点:基本不使用词法特征,整个模型更加简练。使用多个卷积核,提取更多的特征。
缺点:实际上就是一个基本的CNN,所以效果提升不是很明显。
4. CNN with Rank Loss(Santos 2015)
这篇文章整体的模型结构基本未变,仍然是常规的CNN,但有许多细节的创新和尝试,其中最为重要的就是使用Rank Loss 代替原来的 softmax cross-entropy。
- 模型
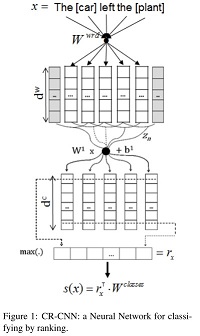
和上文一样就是一个常规的CNN,输入使用word embedding 和 position feature 。不过其固定了卷积核为3。
Rank Loss
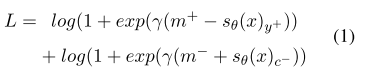
$m^+,m^-:两个边界值。文章中分别取了2.5和0.5。$
$\gamma:一个放大系数,使结果更明显。文章中取2。$
$y^+:正标签。c^-:负标签。文章中只取得分最大的那个负标签。$
整个公式相比于cross-entropy(可以认为只要求正标签的概率接近1),还要求负标签要越小越好,所以最终的结果有所提升。
其他类的处理
在semEval中存在other class 这个分类。作者认为这个分类会造成很大的噪声,因为它将很多类归为了一个类。所以文章在训练时不再划分other类,对于数据集中标为other类的数据计算RL时将第一项的值直接赋0,这也就意味着要求分到确切类的得分要小。在预测时,如果确切类的得分都为负则分为other 类。
实验
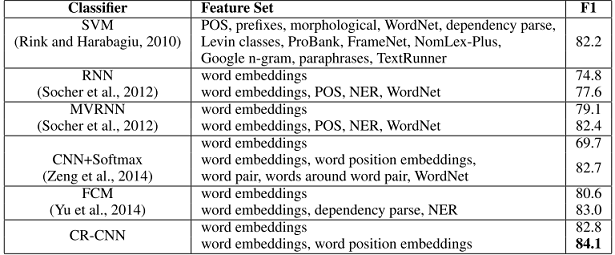
- 整体效果达到start-of-art。
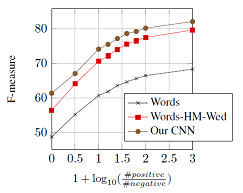
使用Rank Loss 有明显的效果提升。
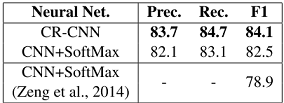
不单独分其他类
前两行统计的是确切分类,可以看到如果训练时不单独分other类能够有效的提高算法结果。
后两行则是单独统计了other分类,可以看到训练时进行单独other分类,对于other分类的准确率还是有帮助的。
但是结合上下数据分析,可以看出是否单独分类对于召回率基本没有影响,但是对于准确率却有影响,进行单独分类会造成更多的数据被分入到确切类导致P值降低。
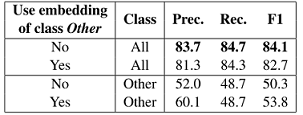
整体来说不进行单独的other分类,能够减少噪声,提高模型表现。特殊的实体位置表示
文章尝试了两种实体位置表示方式:1.用word position表示。2.句子只截取实体到实体,输入的头尾就是实体。
结果很明显,用word position效果好,毕竟截取句子会丢失掉信息。不过可以看出用截取这种方法还有有效的。(我在想是不是可以往实体之前之后一定的位置进行截取,这样可以减少信息的损失还能不用单独的添加位置信息?)
总结
- 尝试许多有意思的东西,比如Rank Loss,不单独分other类,特殊的位置表示方式,很有意思和指导意义。
- 虽然有很多尝试,但整体的网络结构并没有改变,还是基础的CNN所以整体的提升不是很大。
5. RNN (Zhang 2015)
Zhang (2015). Relation classification via recurrent neural network.
这篇文章尝试在不使用额外语言特征的情况下,使用RNN来进行关系提取。
模型
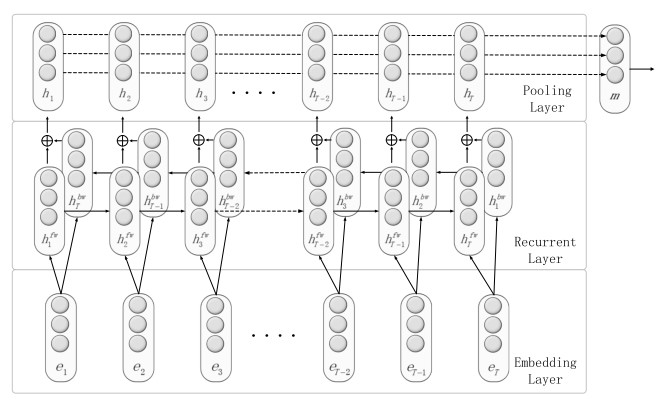
非常基本的双向RNN,但有几个特殊点:
- 对距离信息的处理Position Indicators(PI),直接在句子中加入
来标记。因为RNN是时间序列模型,其能够自己学习相对位置关系所以只需要标记处实体即可。而CNN只能学习局部特征,所以需要人为的添加 距离特征。 - 最后使用了max pooling,并且还实验表示用这种方法比用最后一位输出效果好很多。。(绝逼是因为使用了普通RNN导致对时间序列的保留能力不够强才导致直接使用最后一位输出效果非常非常的差。。。好吧,算是一种特殊的解决RNN短时记忆的方法~)
- 对距离信息的处理Position Indicators(PI),直接在句子中加入
实验
- 整体效果,还不错。也证明了PI的可行性。
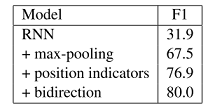
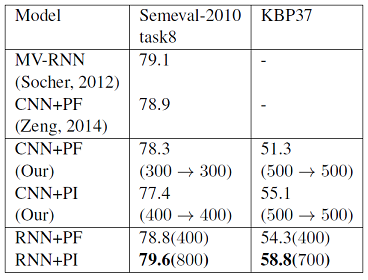
总结
就是一个RNN的尝试,证明了PI的可行性,使得完全没有了人工设计的特征。体现了RNN对于文本这种时间序列输入的优势。
6. Att-BiLstm(Zhou 2016)
Zhou. (2016). Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification. ACL
使用了bi-Lstm+attention的方式,得到了比较不错的效果。
模型
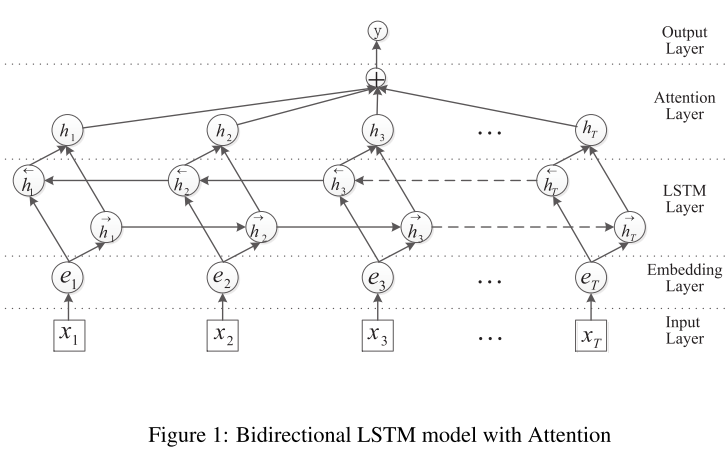
十分简洁常见的模型。
输入也是使用
来标记实体。 bi-Lstm:弥补了上文普通RNN短时记忆的缺陷。
- attention机制:上文使用暴力的max来获取整个文本的特征,attention则为每个输出赋予一个权重更加的合理。
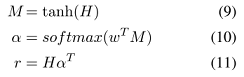
实验
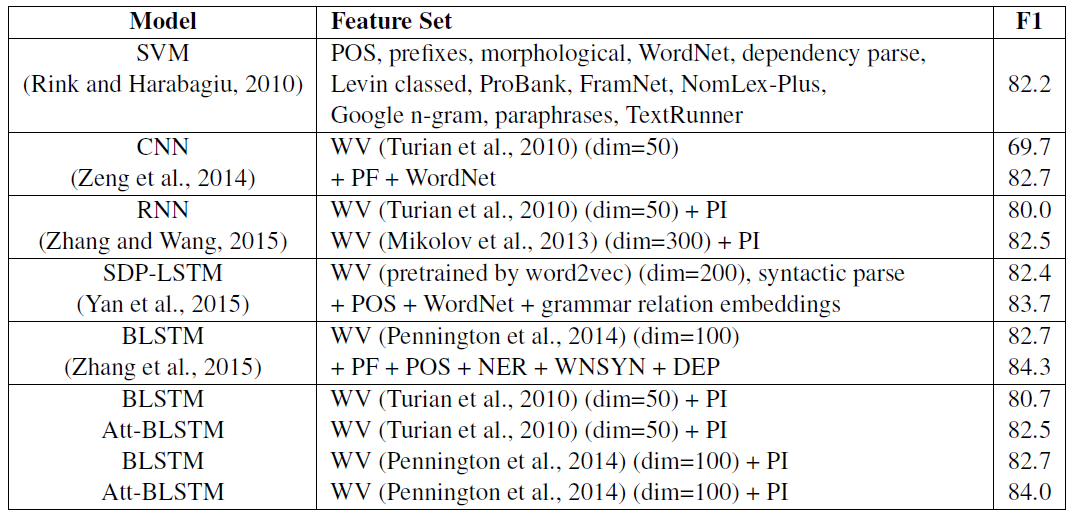
总结
Lstm和attention可以说是现在NLP中的标配方法了,文章也只是将其用在了RE上面,并没有创新点。
7. Multi-Level Attention CNN (Wang 2016)
Wang. (2016). Relation Classification via Multi-Level Attention CNNs. ACL
这篇文章最大的亮点在于:在CNN这种使用了两次Attention,分别强调了输入文档与目标实体的联系、各个卷积核输出与各个类别之间的联系。
模型
看着整体结构还算清晰。
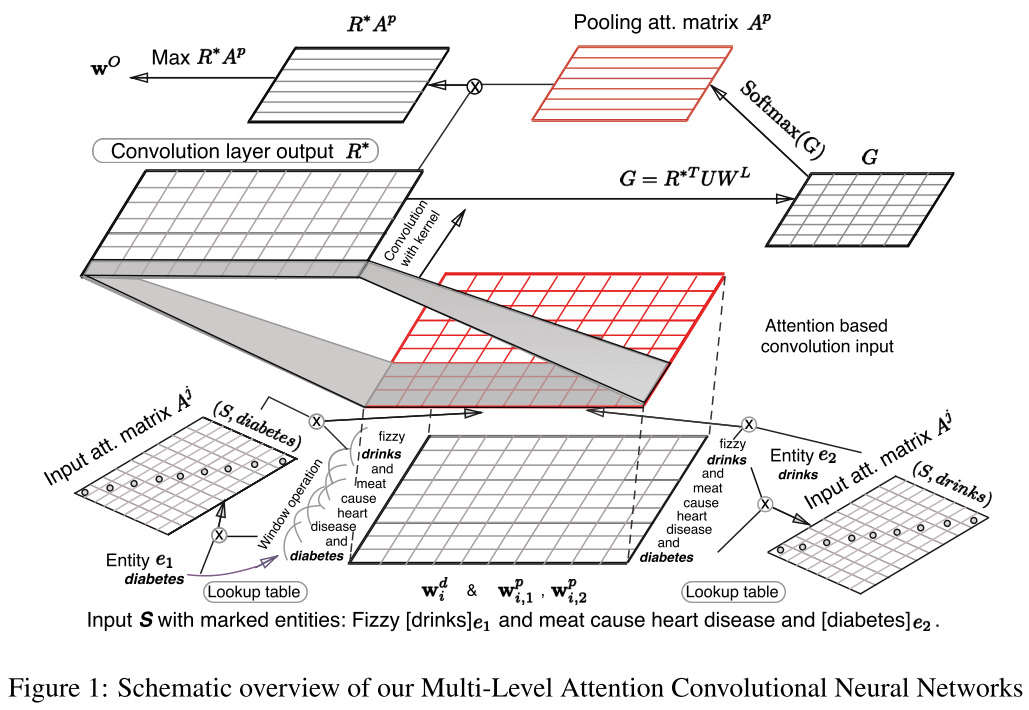
输入
- $w^d_i$:词向量输入。
- $w^p_{i,1},w^p_{i,2}$:相对位置向量,需要训练一个距离映射矩阵。
- $w_i^M = [(w^d_i)^T,(w^p_{i,1})^T,(w^p_{i,2})^T]$ 常规的三个向量合一。
- $z_i=[(w^M_{i-(k-1)/2})^T,…,(w^M_{i+(k-1)/2})^T]^T$ ,又提前确定了卷积核宽K…
input Attention
图中画的是二维矩阵$A^j$,实际上是个对角矩阵,当做一维权重矩阵来看就行了。
- $A_{i,i}^j = f(e_j,w_i)$ ,计算每个词对实体的关系。
- $\alpha_i^j=\frac{exp(A_{i,i}^j)}{\sum_{i’=1}^nexp{A^j_{i’,i’}}}$ ,softMax计算权重。
- 对于这个权重的使用,文章尝试了三种使用方法。
- $r_i = z_i\frac{\alpha^1_i+\alpha^2_i}{2}$
- $r_i = [(z_i\alpha^1_i)^T,(z_i\alpha^2_i)^T]^T$
- $r_i=z_i\frac{\alpha_i^1-\alpha_i^2}{2}$
Convolution Layer
常规的卷积操作。卷积核数$d^c$ 。输出$R^=>维度nd^c $,n为句子长度。
pooling Attention
$G=R^{T}UW^L$ ,$U$就是一个普通的权重矩阵需要学习得到,$W^L$是类别的映射矩阵每个类别能够映射一个向量(类似于词向量矩阵)。$[d^cn][n?][?y]=>[d^c*y]$ 。
$A^P=softmax(G)$ ,可以看成每个卷积核结果对于各个分类的概率。
output
- $w^O_j=max_j(R^A^P)_{i,j}$ =>$[yd^c][d^cn]=>[y*n]=max_j>[y]$ 。可以简单理解为通过每个卷积核对于各个分类的概率结合每个卷积核在各个位置得到的值获得每个位置的对于各个分类的概率,通过max保留各个分类的最大概率。最终输出的是各个分类的评分。
Loss function
$\delta_{\theta}(S,y)=||\frac{w^O}{|w^O|}-W^L_y||$ ,计算输出与各个分类向量的距离,作为得分。
$L = [\delta_\theta(S,y)+(1-\delta_\theta(S,y^-))]+\beta||\theta||^2$ ,这一步和之前的Rank Loss类似,不止考虑了正确类别的得分要大,还要求最大的错误分类的得分要小。
实验
- 88%得分还是6的啊。
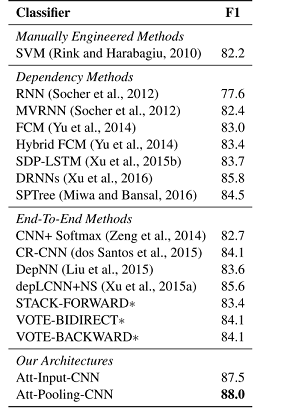
三种不同的input attention使用方式:

可以看到新的loss function和input attention 对提升非常的明显,而pooling attention有一定的提升。

总结
优点:
- input attention的使用非常的巧妙,attention的优势在于无视距离地获得关系,而CNN的弱点在于对位置信息的获取非常差,input attention 的使用极大的加强了模型对于远距离关系学习能力。所以input attention 的使用很大程度的提升了模型效果。
- margin based ranking loss,使用embedding的逼近作为距离函数。个人认为还是ranking loss的思想起到关键效果,避免了cross-entropy只关心正确标签的局限性。
缺点:
- 第二个pooling attention 的使用有点鸡肋,它本意想放弃max pooling这种暴力的方式,选择更加细节的计算每个词的各个分类概率,但是最后还是选择了最大值。。。嗯这和从一开始就选择最大值效果提升不大。这个操作还大大复杂化了模型,使得模型变的收敛困难!
总结
- CNN中需要额外的position embedding。RNN则不需要。
- Rank Loss 效果优于softMax。
- attention的使用能有效的提升模型质量。
- 主要使用了Attention、CNN、RNN。大体的准确率已经定下来了,不太会有很大的提升了,除非有新的模型出现。接下来就是在各个细节上进行打磨,排列组合这些模块。
##Distant 半监督学习
前面也提到了对数据标关系实在太麻烦了。。带标签的数据集获得太困难,所以就想尽办法利用无标签数据。基于种子的半监督,结果是学习出大量pattern,这并不是我们需要的,而且用这种方法得到的标签数据质量太差。Distant的半监督方法相对来说就好一些,它只是用确定的关系实体自动去打标签,这个过程不涉及学习,所以获得的数据质量就高很多,当然还是存在大量的噪声错误标签。
1. Piecewise Convolutional Neural Networks(Zeng 2015)
Zeng (2015). Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks. EMNLP
这篇文章有两个十分有趣的改进点:分段CNN和多实例学习。
模型
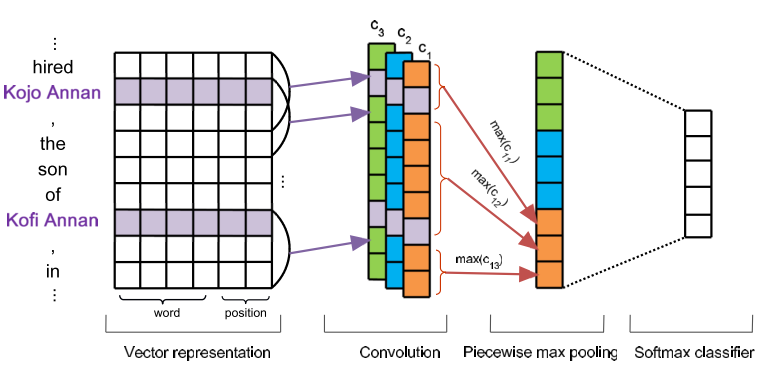
整个模型非常常规,输入用word embedding + position feature。用多个卷积核进行卷积操作。
分段CNN,PCNN
之前在pooling层大部分使用Max pooling。这样做对文本的时序信息丢失是很大的,所以这篇文章的一个亮点在于使用了分段的Pooling,其将整个文本根据实体位置分为3段,然后分别对这3段求取最大值。这样一来就能够保留下一定的时间信息。
多实例学习 Multi-instance Learning
因为数据集是通过Distant方法得到的,所以存在很多标错的数据,存在大量噪声。如果还是用一般的训练方式,很容易造成模型无法收敛。所以这篇文章使用了多实例学习的方式。
多实例学习将同一类的数据实例放在一起形成一个Bag。训练的目的不再是追求每个实例的准确,而是降低为每个bag的准确,这样一来就能够大大降低噪声数据带来的影响。
具体:
- 假设现在有T个bag${M_1,M_2,…,M_T}$ 。每个bag中有$q_i$个实例$M_i={m_i^1,m_i^2,…,m_i^{q_i}}$
- 训练时每个batch,随机从一个bag中选取batch-size数量的实例进行训练。
- 每个实例都能获得自己的各个关系概率。
- 这个批次数据的标签为y,那么从所有实例中获得y概率的最大值,这个概率作为这个批次的y概率。
- 整个模型的目标为最大化这个y概率。
- 嗯。。。整个流程下来,感觉一个批次只训练了一个最像y的实例。。。嗯。算是自动排除了噪声。。
实验
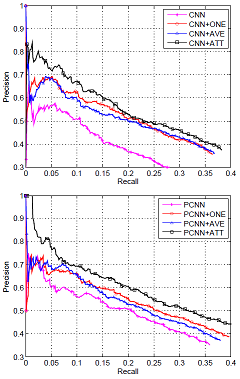
比较其他模型,效果很好。
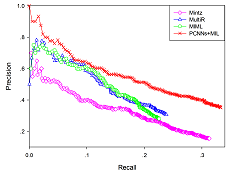
可以看出PCNN对于P,R都有明显帮助。MIL则是会降低P值提升R值。
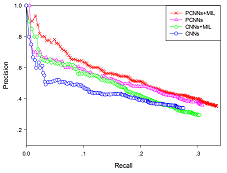
总结
- PCNN,用巧妙的方法在pooling层保留了部分序列信息。
- 多实例学习,这个文章的处理十分暴力,等于每个批次只训练最正确的那个实例,无视其他实例(全当做噪声)。嗯。。这样做能很好的处理噪声。但对于数据的使用效率是很低的。。期待看到更巧妙的多实例学习处理方式~
2. Selective Attention over Instances (Lin 2016)
哈哈哈,这篇文章对于上篇文章数据使用率低的问题进行了解决。不再专注于最接近的instance,选择使用均值和利用attention计算权重从而进行加权。
模型
没什么特点,就是上面的PCNN。
attention
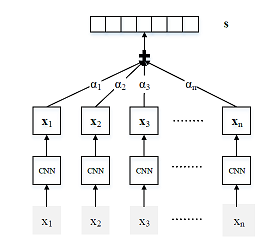
这个就是这篇文章修改的地方。上篇文章只使用了最接近目标类别的实例进行学习,造成信息大量丢失。所以这篇文章使用attention来求取各个实例的权重,然后加权进行学习。
- 文章对每个类别学习了一个对应向量,每个实例的输出与类别向量的乘积作为相关度,softmax求出各个实例的权重,加权相加获得最后的输出。嗯。。就是一个正常的Attention操作~~
实验
效果还是挺明显的。实验中取均值的方式要差于取最大值的,说明取均值噪声影响仍然很大。
总结
在上一个模型的基础上添加了一个attention,减少了信息的损失。
需要注意的是,训练和预测阶段的模型是不一样的,预测时需要和每个分类的attention向量进行相乘,取最大值对应类别作为预测结果。
3. Multi-instance Multi-label CNNs (Jiang et al., 2016)
Jiang (2016). Relation Extraction with Multi-instance Multi-label Convolutional Neural Networks. Coling
这个模型仍然是对第一个模型的改进。其关注点在于:多标签。因为实际中两个实体之间可能有多种关系。
该模型假设a relation holding between two entities can be either expressed explicitly or inferred implicitly from all sentences that mention these two entities.
- 模型
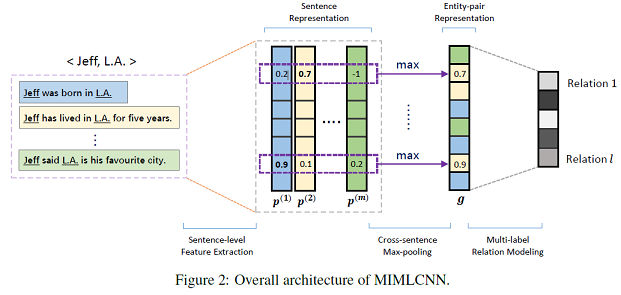
bag的内容
不同于之前的模型将同一分类的数据放在一起,MIMLCNN则是将同样实体的数据放在了一起,这和它的假设一致,这样一来一个bag中就有了多个标签,从而能够用来训练多标签任务。
句子级别特征提取
常规的PCNN。
跨句最大池化
之前的模型都是先得到每句话的分类向量,再进行选择、组合。这个模型则是先合并句子向量再得出概率分布。操作称为“Cross-sentence Max-pooling”,就是直接每位取max。最后再全连接输出类别大小的预测向量。
损失函数
这一步的操作有点奇怪,模型没有用常规的softmax求概率,而是对每个分类用sigmod函数单独求各自的概率。。。。并设置了两个损失函数。。。十分奇怪的操作~
$p(i|M,\theta)=\frac{1}{1+e^{-o_i}},i={1,2,…,l}$
$Loss_{sigmoid}=-\sum_{i=1}^ly_ilog(p_i)+(1-y_i)log(1-p_i)y_i\in{0,1}$
$Loss_{squared}=\sum_{i=1}^l(y_i-p_i)^2$
实验
可以看到整个模型相比于PCNN有着比较明显的提升。
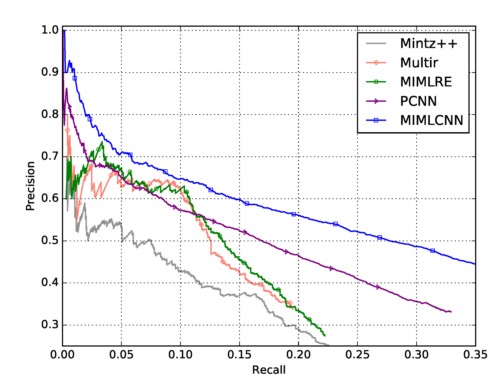
总结
整个模型最大的亮点在于多标签的学习。其假设两个实体之间是存在多个关系的,相比于之前的假设这个假设没有那么严格,更加合理。不过整个模型还有很多可以修改的地方,比如pooling层直接使用max值可以尝试其他的融合方式。损失函数可以尝试用softmax进行概率分布比较,而不是用y的0,1比较。
4. Memory Network based (Feng 2017)
Feng,(2017). Effective deep memory networks for distant supervised relation extraction. IJCAI
这篇文章的特点在于大量使用了attention机制,通过attention学习实体与上下文之间的关系、学习关系之间的依赖关系。整个模型是一个多实例多标签模型。
模型
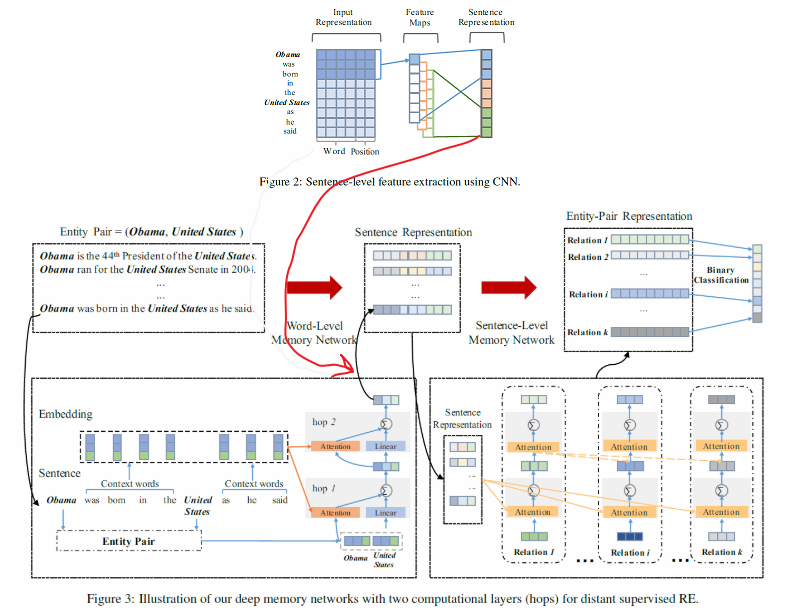
bag内容
和上一个模型一样,bag中是包含相同实体的句子。用于多标签任务。
Sentence-level feature
句子级别的特征采用PCNN来提取。
word-Level Memory Network
使用attention来提取词级别的特征,用于获得实体和其他词之间的上下文关系。
模型使用了两层attention,第一层用两个实体连接作为目标向量,第二层则以第一层的输出作为目标向量。
Sentence Representation
将句子级的特征和词级的特征连接起来作为整个句子的表征。
Sentence-Level Memory Network
也是两层attention,第一层attention提取句子和各个类别之间的关系,第二层提取各个类别之间的关系。
Binary classification
最后对每个类别做一个sigmod的二分类,使用和上个模型一样的损失函数。
$Loss_{sigmoid}=-\sum_{i=1}^ly_ilog(p_i)+(1-y_i)log(1-p_i)y_i\in{0,1}$
实验
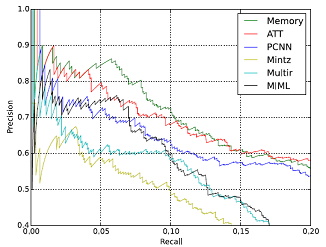
总结
一个主要使用attention机制的多实例多标签模型。利用attention引入实体与词的相关性、词与标签的相关性、标签与标签的相关性。有点transformer的影子。